Chapter 2
Descriptive Analytics 1: nature of data, statistical modeling, and visualization.
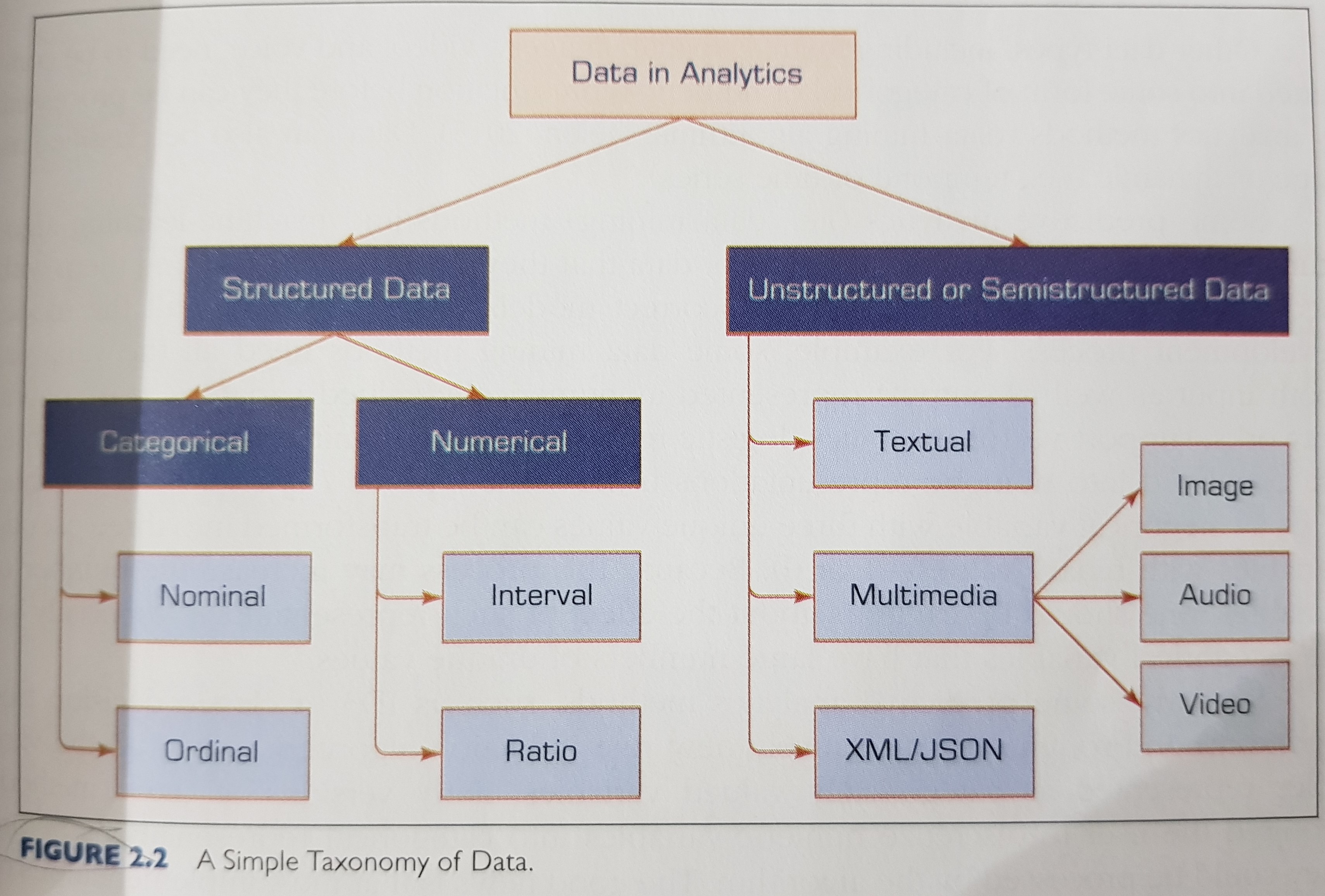
Data (datum in singular form) referes to a collection of facts usually obtained as the result of experiments, observations, transactions, or experiences.
Types of Data:
1. Acquiring Data
Traditional vs. modern data collection:
- Traditional == manual data collection (e.g., surveys).
- Modern == automated data collection, resulting in an increase in:
- data collection volume.
- data quality and integrity.
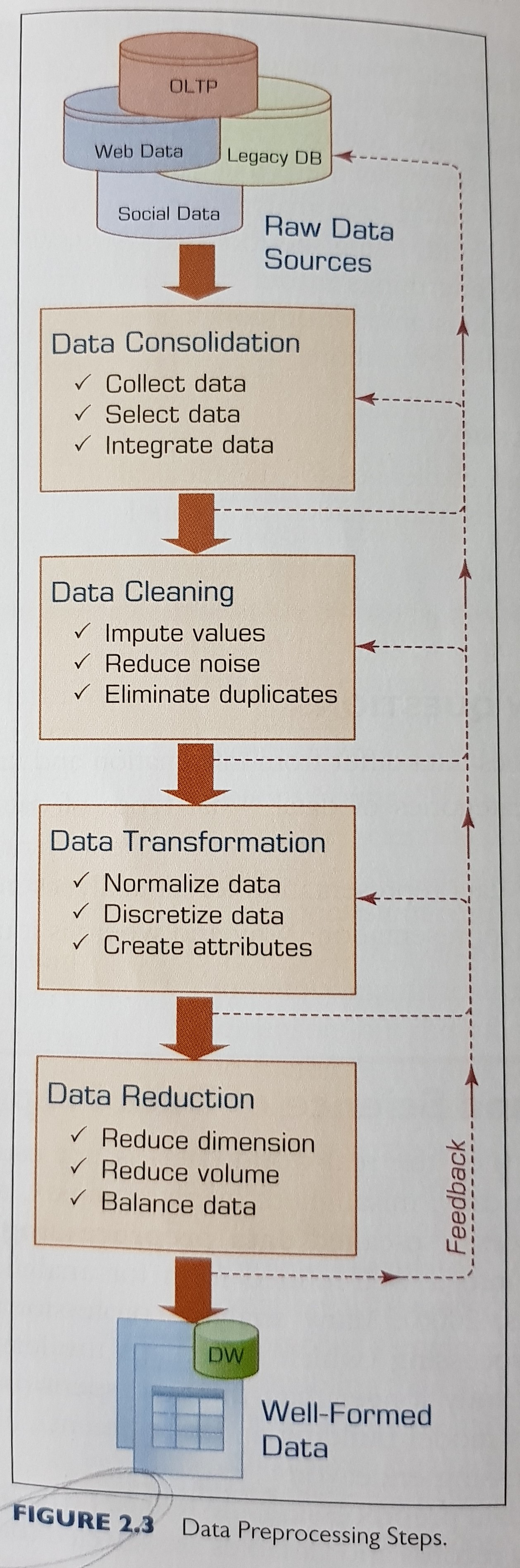
2. Managing/Processing Data For Analytics
Important high level points:
- Improve cleanliness through improved master data management and governance (data hygiene is important).
- It is almost imposible to underestimate the value proposition of data preprocessing. It is one of those time-demanding activities where investment of time and effort pays off without a perceivable limit for diminishing returns.
Metrics that define the readiness level of data for an analytics study: - data source reliability (be as close to the data source as possible). - data accuracy and consistency. - data granularity (deep dive, you can always aggregate later). - data richness (i.e., comprehensive) and of enough quantity. - data accessibility/security/privacy.
Data in its original form is not usually ready to be used in analytics tasks, it needs to be preprocessed (sometimes in different forms, depending on the type of analytics used).

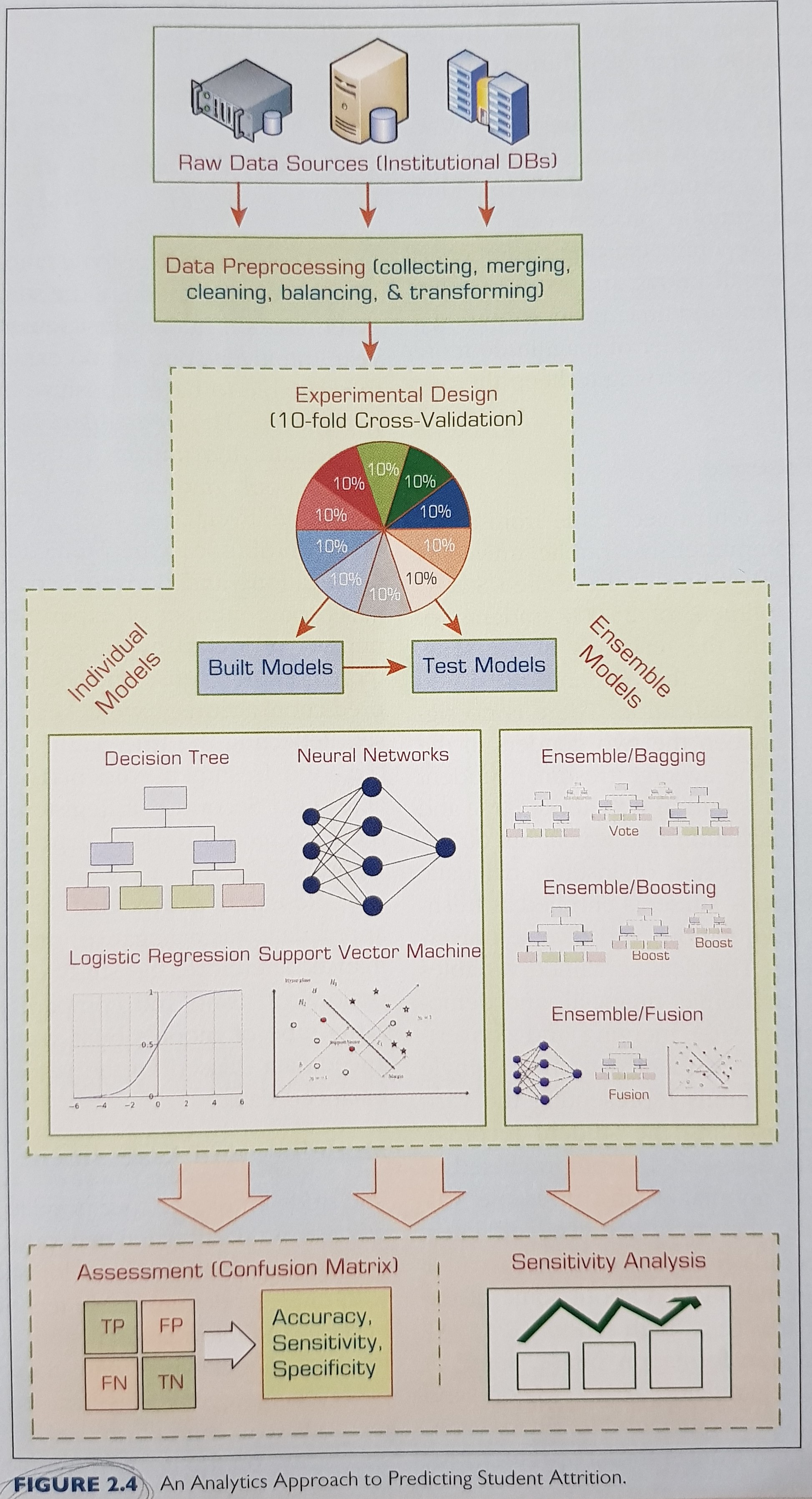
3. Predictive Analytics
High level points on predictive analytics:
- For skewed data, straightforward random sampling may not be sufficient, and stratified sampling may be required.
- Research has shown that balanced data sets tend to produce better prediction models than unbalanced ones.
- Even though the prediction results can be only slightly better than individual models, ensembles are known to produce more robust prediction systems compared to a single-best prediction model.
4. Statistics - General
Statistics is a collection of mathematical techniques to characterize and interpret data.
Some important / frequently used measures for…
- Central tendency:
1.1. mean
1.2. median (the middle value in a sorted data)
1.3. mode (the most frequent data)
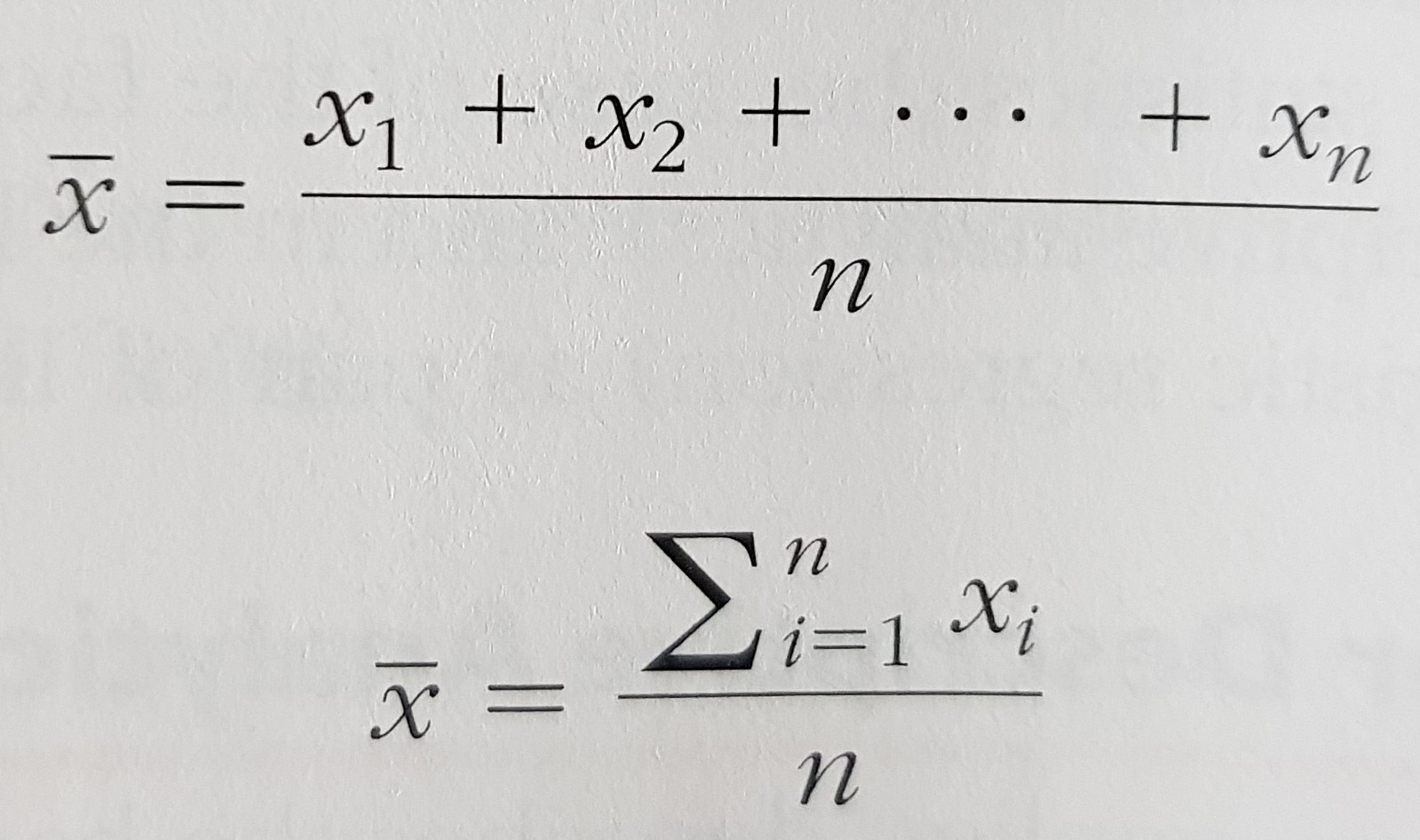
- Dispersion:
2.1. range
2.1. variance
2.1. standard deviation
2.1. mean absolute deviation (MAD)
2.1. quartiles and interquartile range
2.1. box-and-whiskers plot
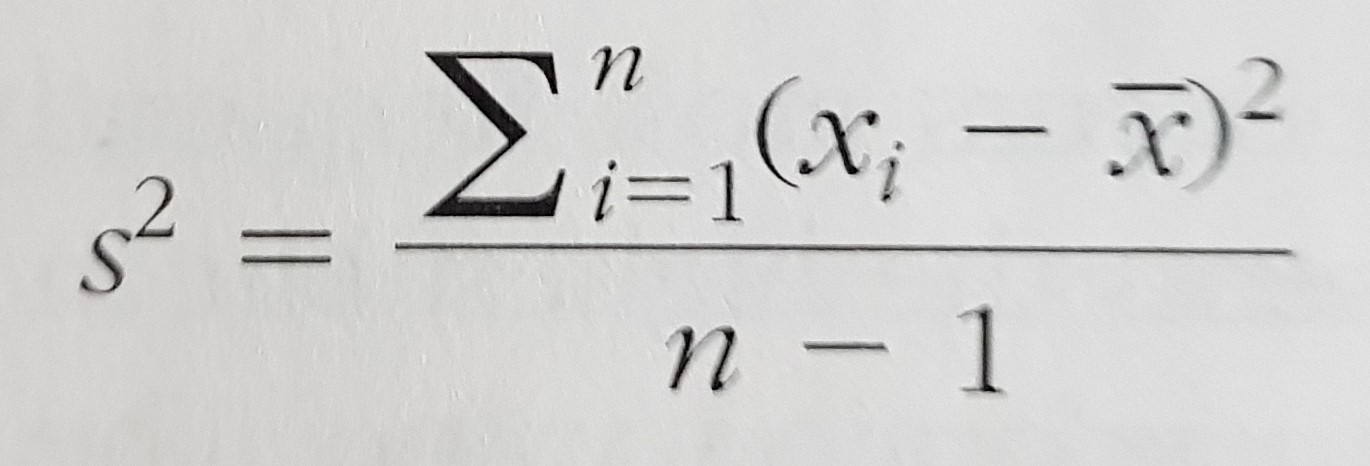
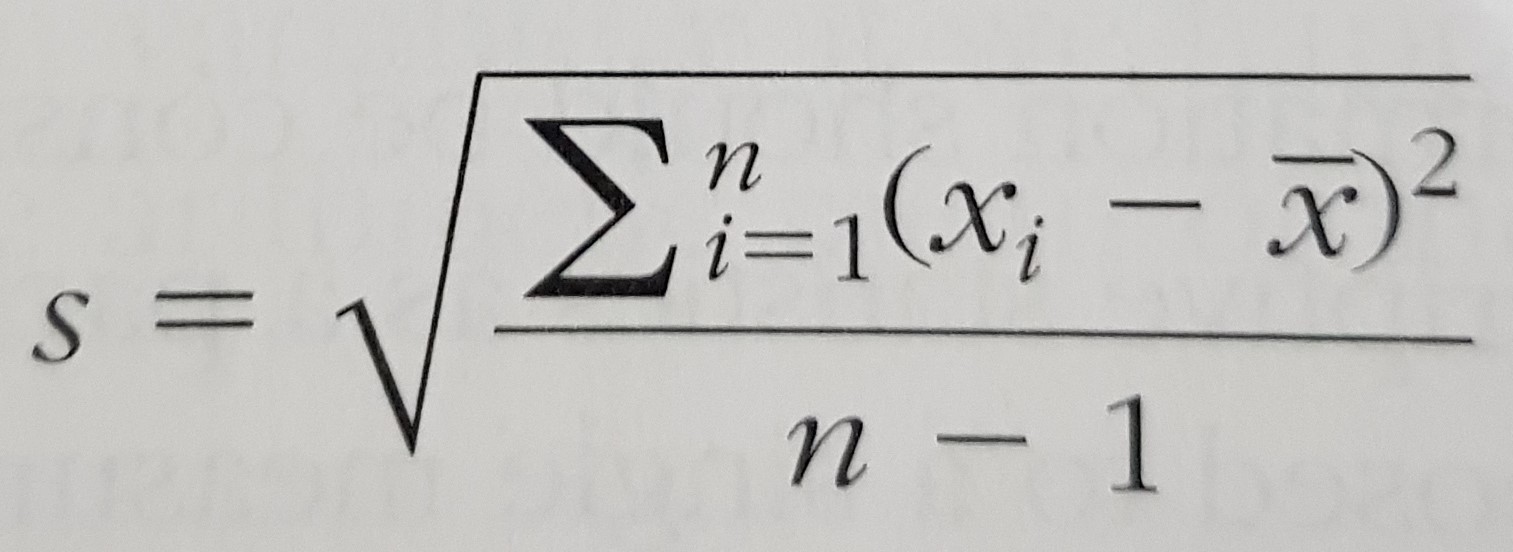
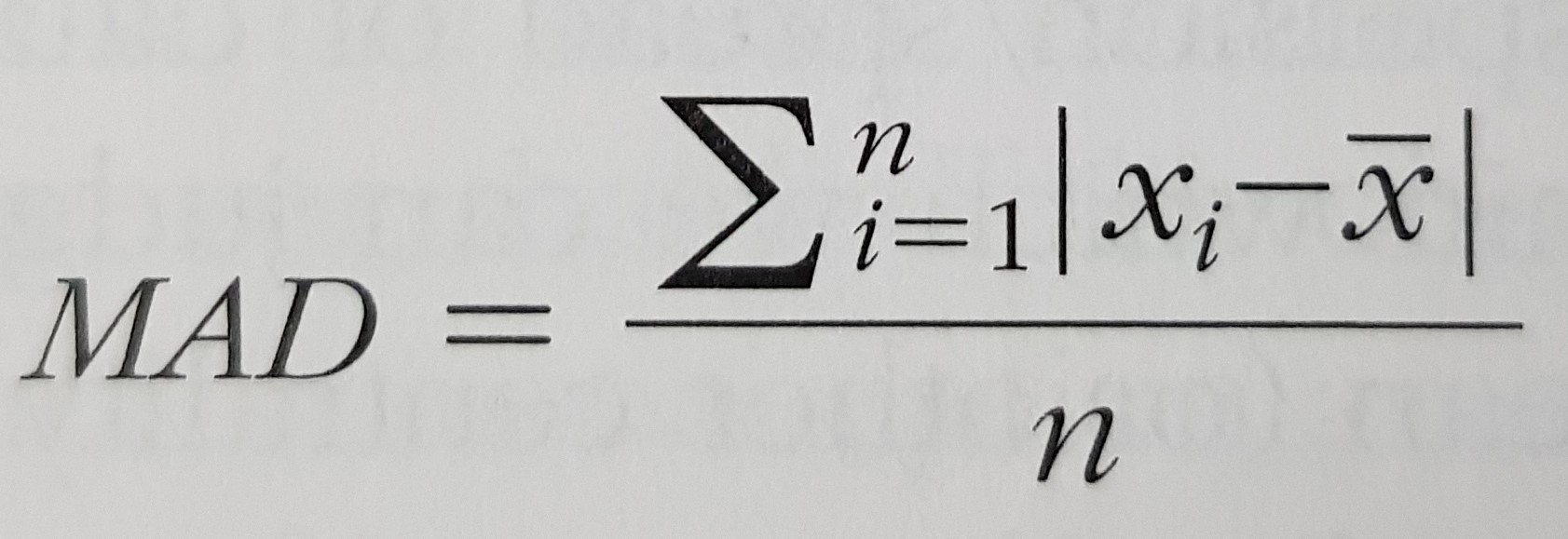
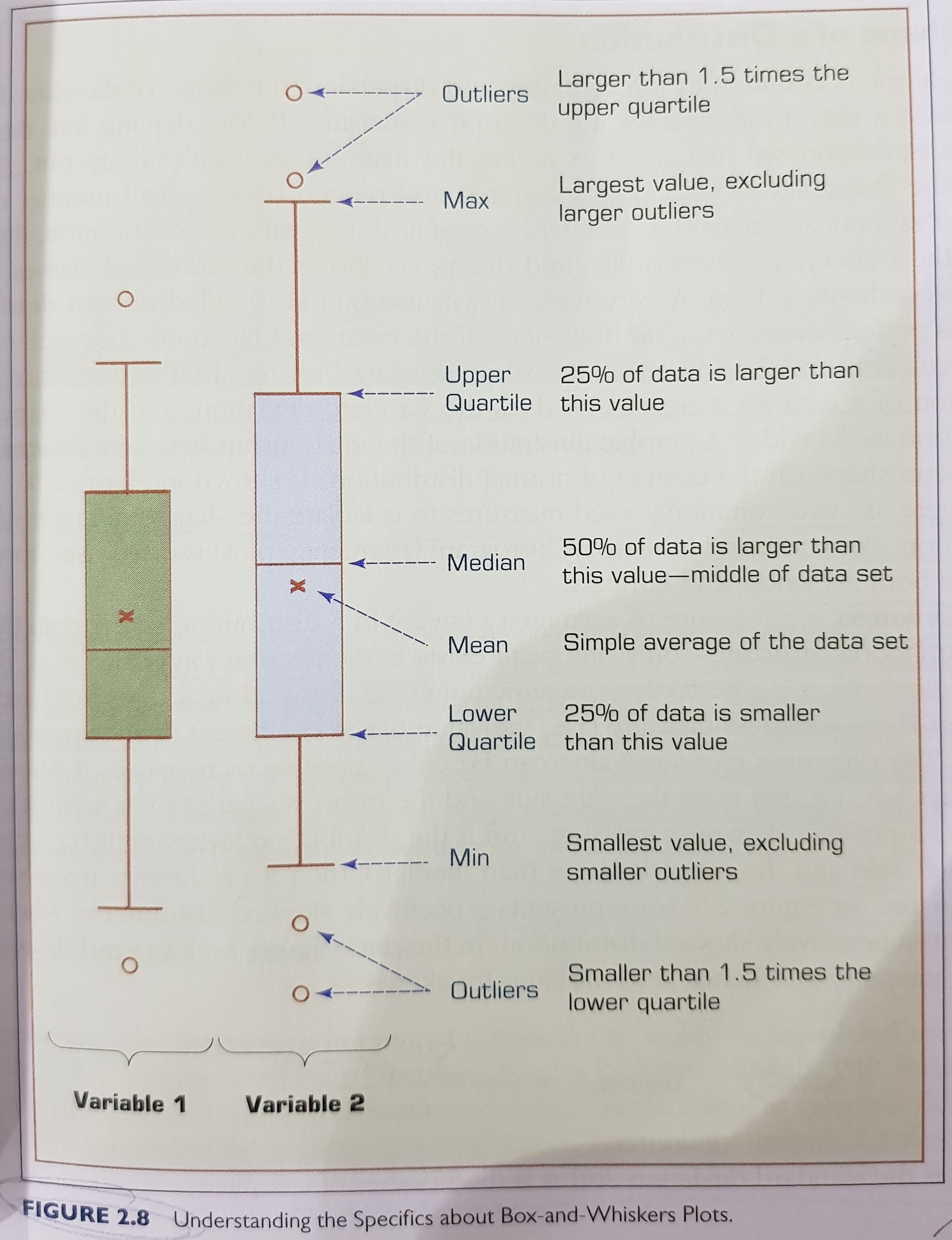
- The shape of a distribution:
3.1. a histogram is normally used
3.2. skewness (sway to the left or to the right)
3.3. kurtosis (high peak or more of a flat distribution)
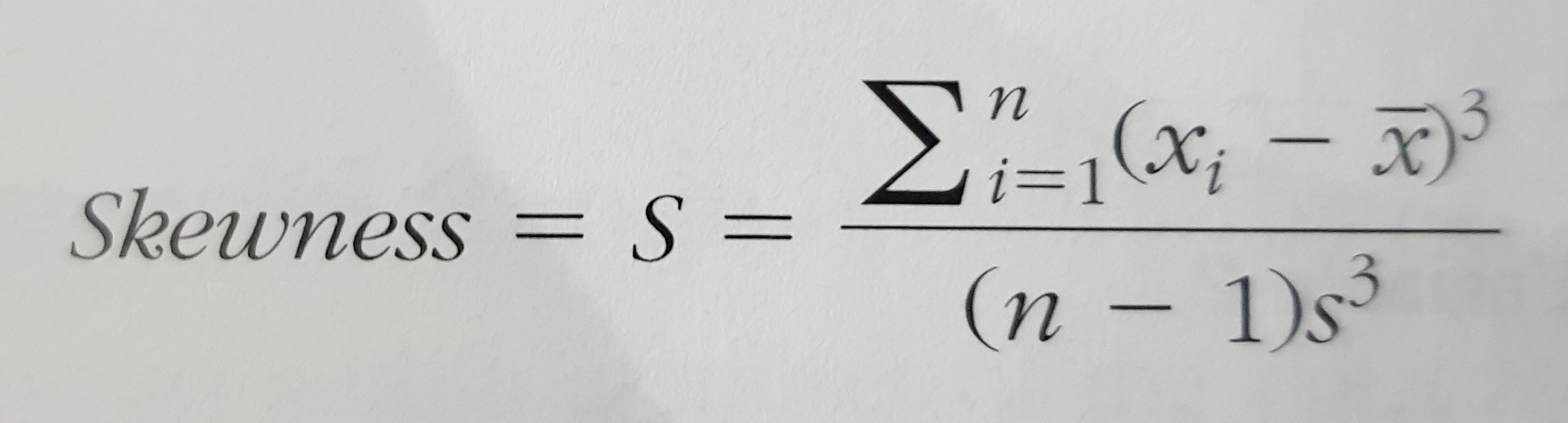
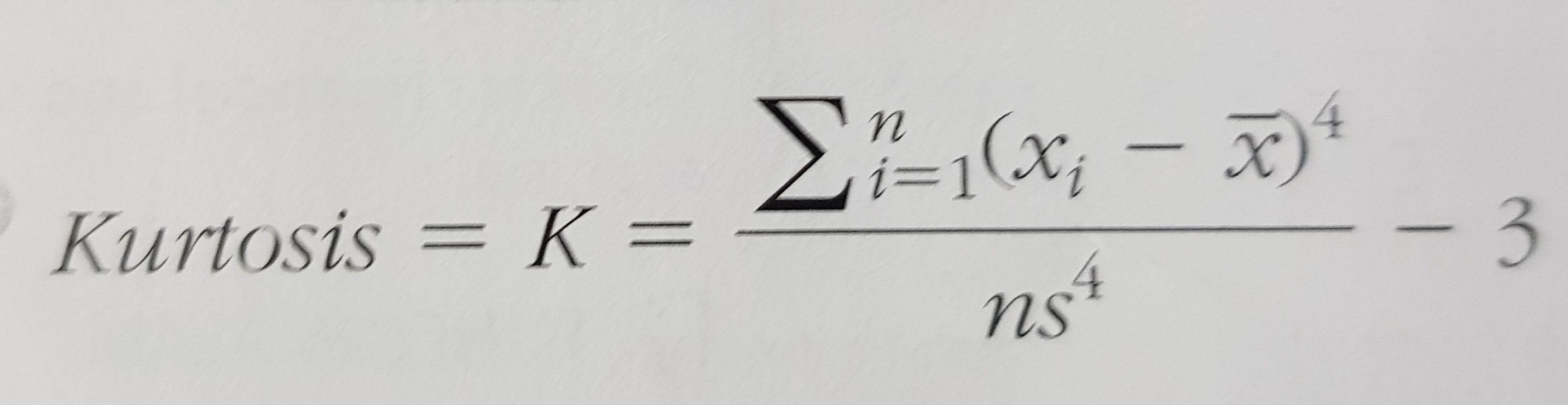
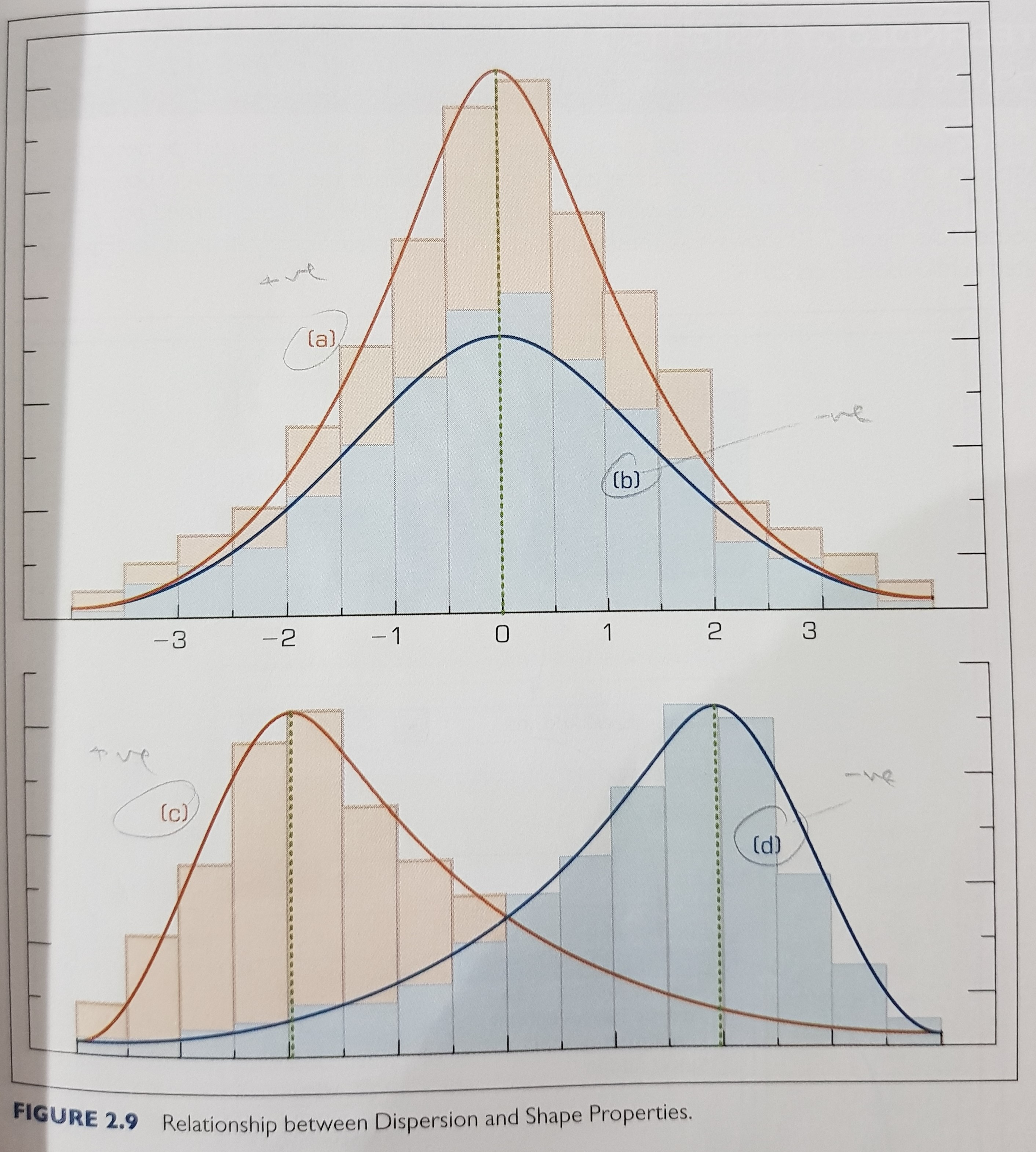
Note:
- Excel has a nice way of calculating descriptive statistics.
- For python pandas, you can use the describe method.
5. Statistics - Correlation and Regression
Regression is used for:
- hypothesis testing.
- prediction/forecasting.
Before developing a regression model however, visualize your data by using a scatter plot.
How do we know if the model is good enough (numerical data)?
- R-squared (explained variance by the model, ranges between zero and one, widely used)
- RMSE
- F-test
All of these three meaures are based on the sum of squared errors.
Assumptions of linear regression:
- linearity
- independence
- normality
- constant variance/homoscedasticity
- mulicollinearity
Correlation =/= regression:
- correlation can be zero, even though there is a relationship explained by a non-linear regression.
- correlation == association, while regression == causality.
- unlike regression, correlation is symmetric.
Logistic regression is similar to linear regression, except that it is used for categorical target variables.
- logit transformation == link function
6. Statistics - Time Series
A time series is a sequence of data points, spaced with uniform time intervals.
Time series forecasting is the use of mathematical modeling to predict future values based on previously observed values. It assumes that all explanatory variables are aggregated and consumed in the response variable’s time-variant behavior.
The time series pattern is decomposed into its main components:
- random variation.
- time trends.
- seasonal cycles.
Regression vs. time series forecasting:
- regression uses independent variables to predict dependent variables.
- time series forecasting on te other hand is focused on extrapolating on the time-varying behavior of the same variable that you are trying to estimate its future values.
One method used in time series forecasting is ARIMA. The accuracy of the method is assessed by computing its error via:
- MAE
- MSE
- MAPE / SMAPE
Note: Each one of them emphasize a different aspect of the error.
7. Business Reports, Dashboards, and Visualizations
Information is essentially the contextualization of data.
Business reports can fulfill many different (but often related) functions:
- to ensure that all departments are functioning properly.
- to provide information.
- to provide the results of an analysis.
- to persuade others to act.
- to create an organizational memory.
Keys to a successful report:
- clarity.
- brevity.
- completeness.
- correctness.
The most distinctive feature of a dashboard is its three layers of information:
- monitoring (overall picture)
- analysis (use a story/narrative)
- management (recommend/suggest an action to take, or at least make it obvious enough)
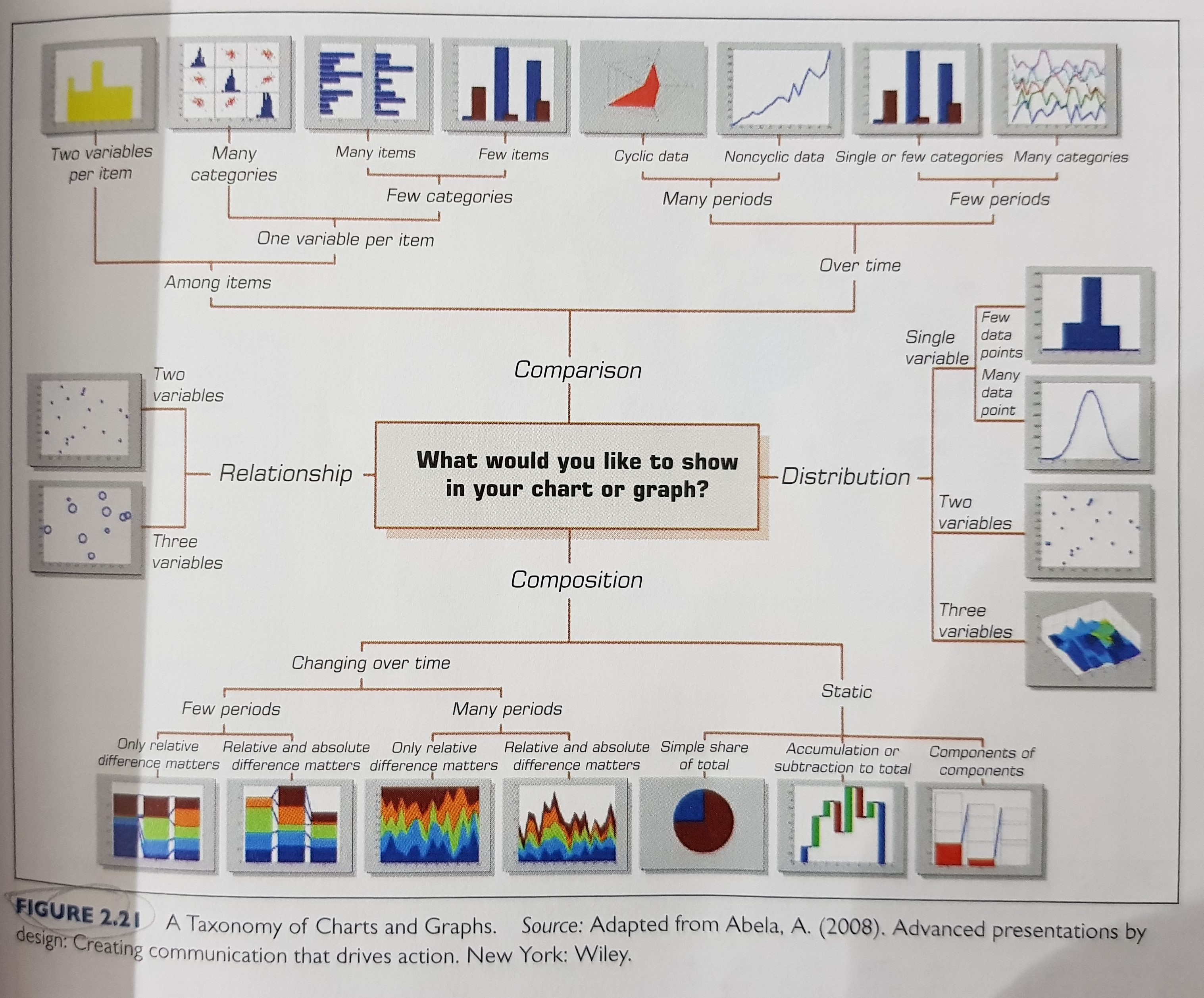
Which data visualization should I use?