Chapter 4
Predictive Analytics 1: data mining process, methods, and algorithms.
- knowledge discovery == data mining
- Difference between statistics and data mining:
- statistics == well defined proposotion / hypothesis
- data mining == loosly defined discovery statement
1. Data Mining Methodologies
CRISP-DM process:
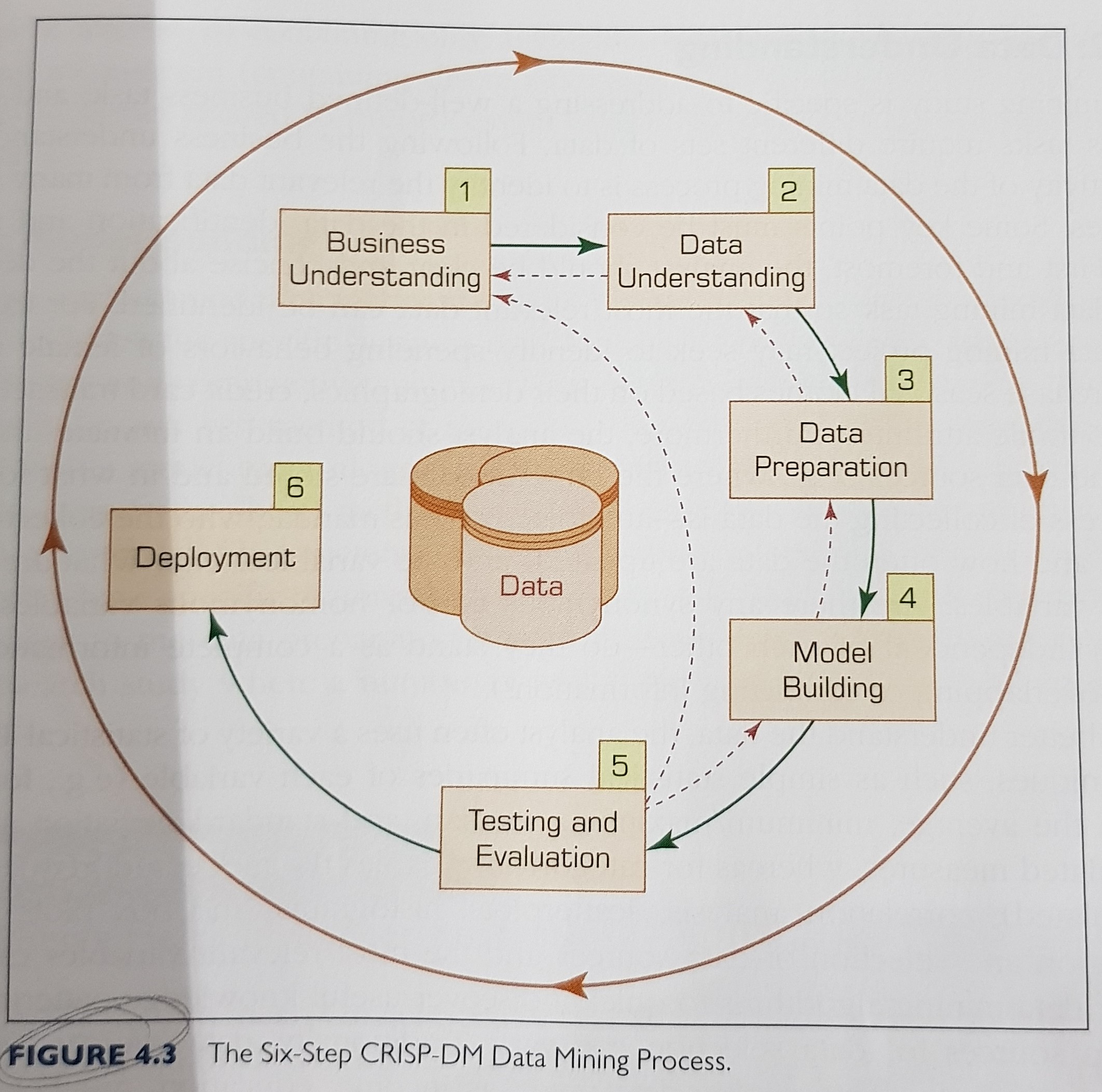
Note: becase later steps are built on the outcomes of the former ones, one should pay extra attention to the earlier steps in order not to put the whole study on an incorrect path from the onset.
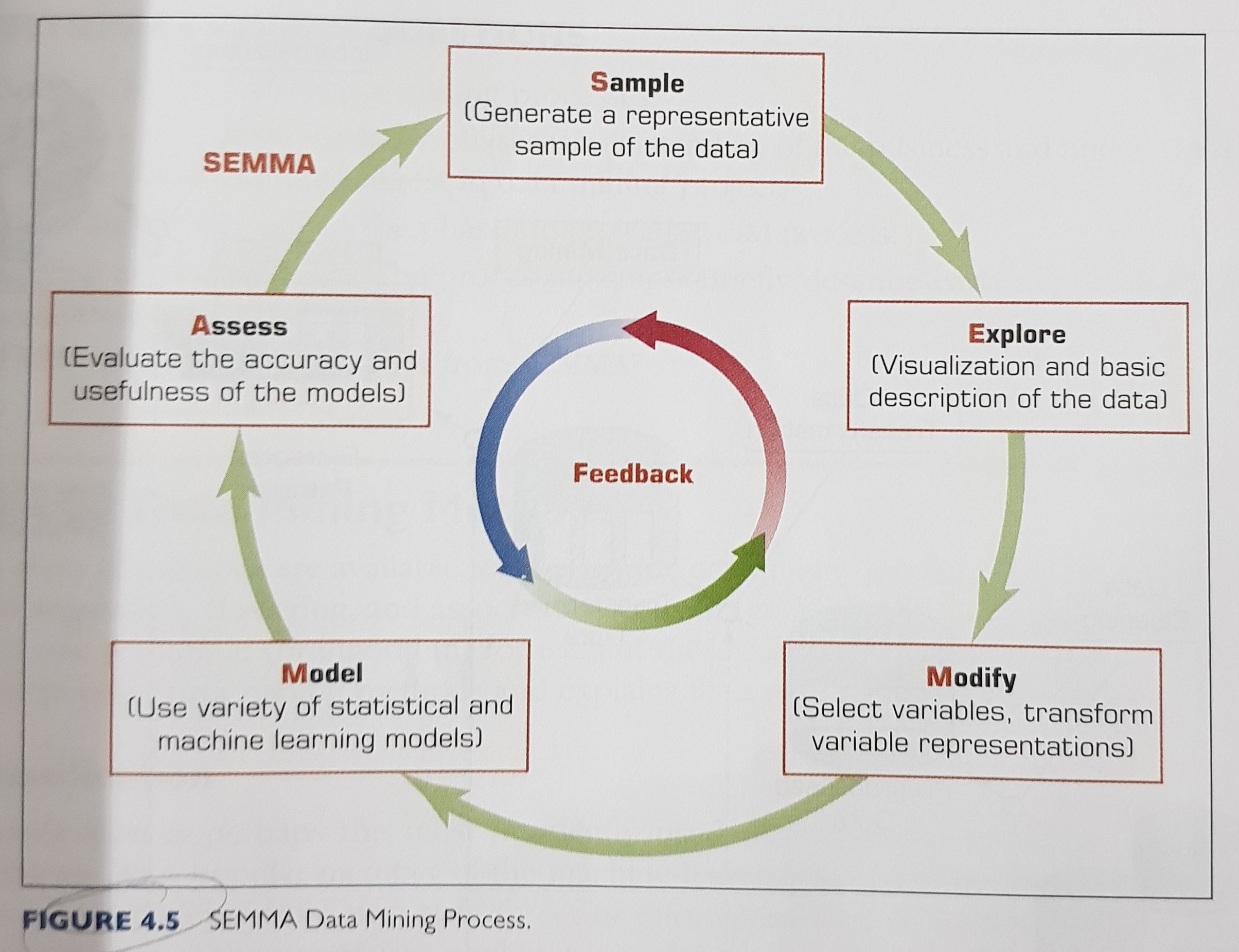
The SEMMA data mining process:
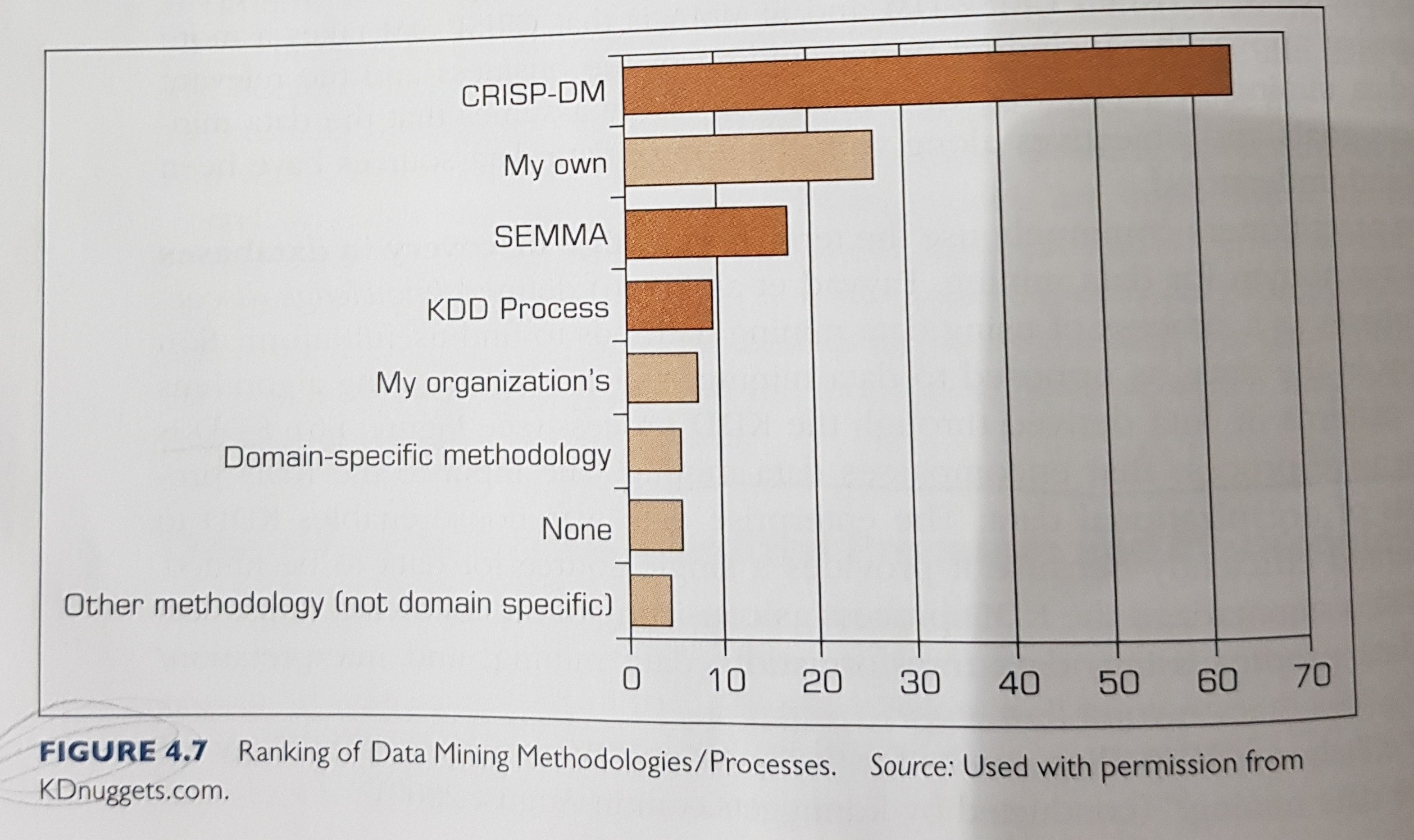
Ranking of DM methodologies:
2. Model Building
- Proper formulation of the problem / solution you want to come up with:
- begin with the end in mind.
- Identifying data sources and working on preparing the data for analysis and model building:
- this step often takes a lot of time, make sure enough time is allocated here.
- as previosuly mentioned in chapter 2 notes…
“It is almost imposible to underestimate the value proposition of data preprocessing. It is one of those time-demanding activities where investment of time and effort pays off without a perceivable limit for diminishing returns.”
- optional, data mining tasks can be used here to create new features, serving as input for your model.
- optional, apparently nowadays there is such a thing called a “data broker” and you can use them to get data, see this example.
- General methods for splitting the data:
- train / test.
- train / validation / test (validation is used during model building to avoid overfitting).
- Specialized methods for splitting the data:
- taking a stratified instead of a random split.
- k-fold cross validation —-special case—-> leave-one-out validation.
- bootstraping (sample with replacement for training).
- Applying data mining tasks and methods:
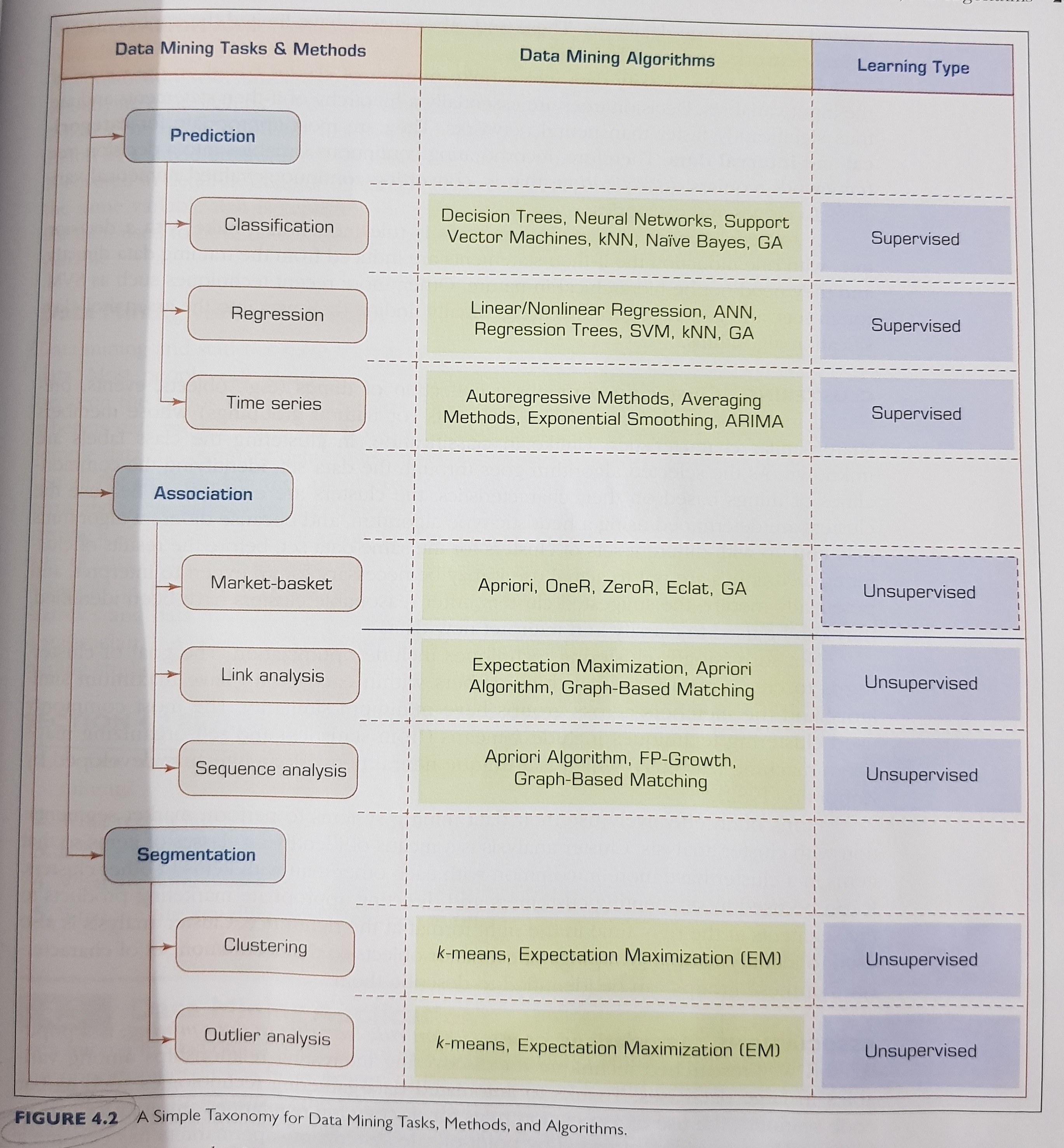
- Optional, making an ensemble:
- ensembles combine information from two or more models.
- usually, an ensemble is more robust than using a single model.
- ensembles can be homogeneous or heterogeneous.
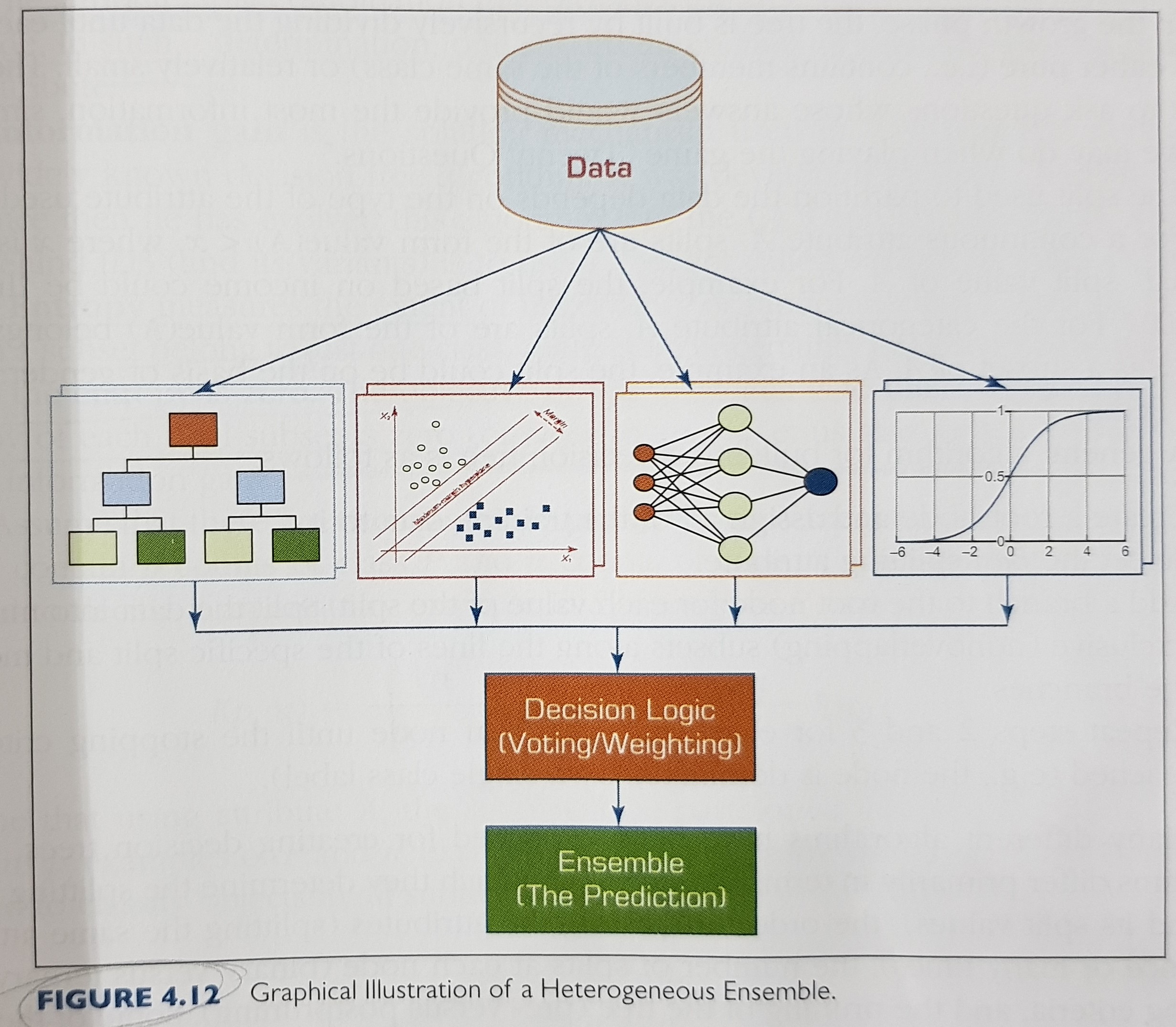
- popular ensemble methods:
- bagging, used by the random forest algorithm.
- boosting, used by the adaptive boosting algorithm.
- for more information about the difference between the two methods, see this article from kdnuggets.
- Model assessment:
- several factors are considered in assessing the model:
- predictive accuracy
- speed
- robustness
- scalability
- interpretability
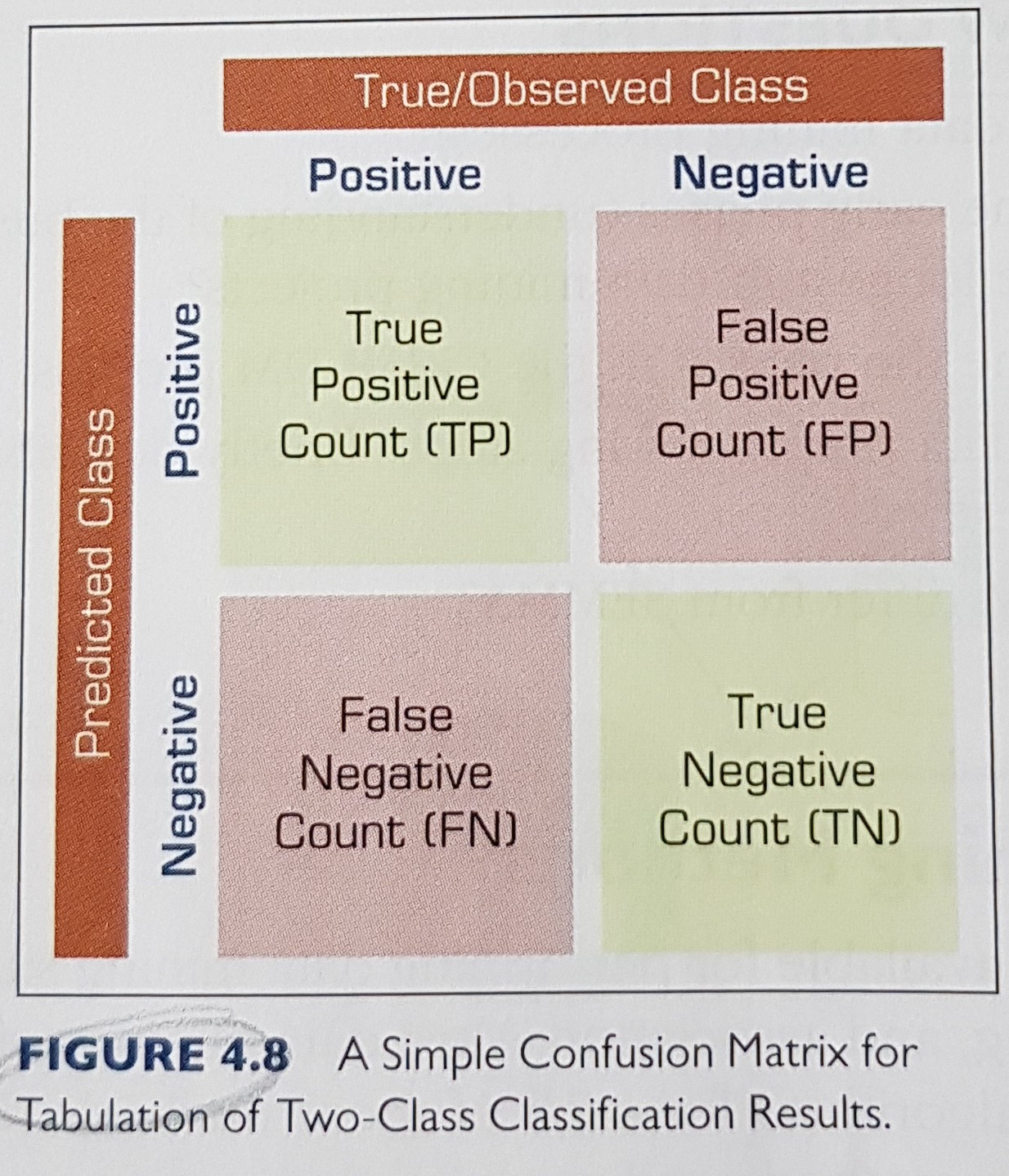
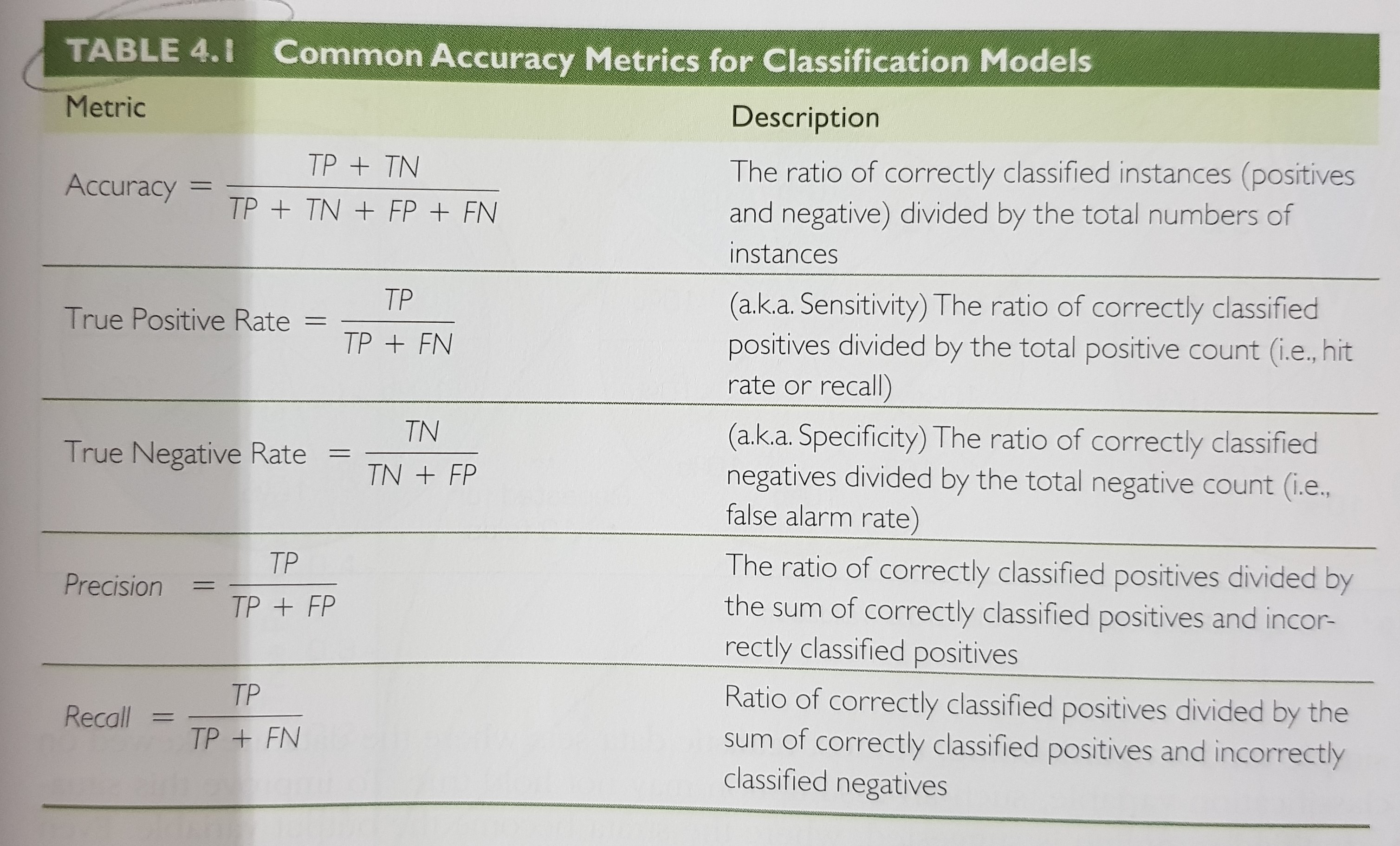
- for predictive accuracy we can use the confusion matrix and its resulting metrics / calculations:
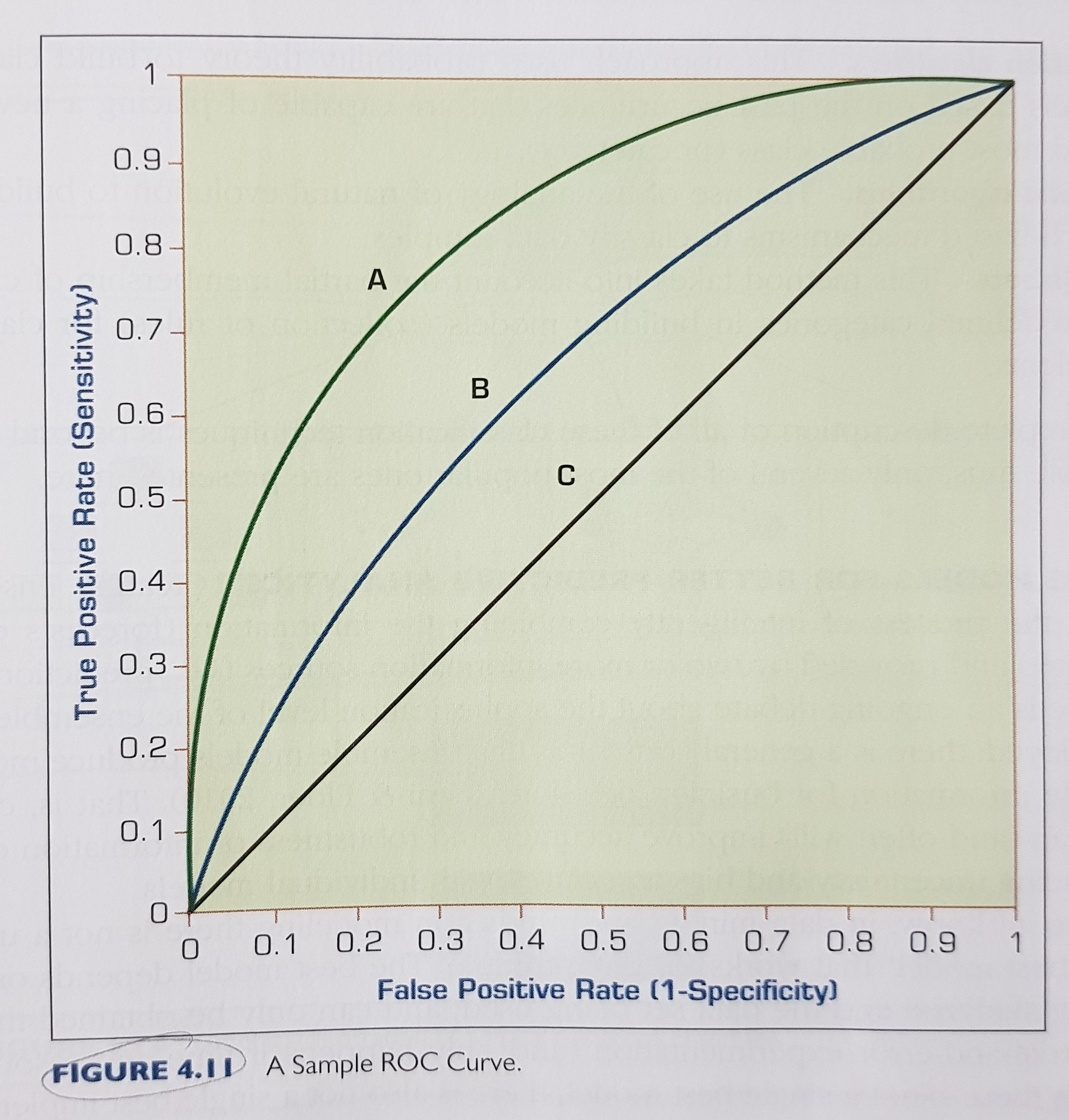
- sometimes we can use a sensitivity analysis approach, such as using the ROC and the AUC:
3. Mistakes Often Made in Practice and Some Practical Tips
Mistakes made in practice:
- Selecting the wrong problem for data mining.
- No expectation management.
- Beginning without the end in mind.
- Defining the project around a foundation that your data can’t support.
- Leaving insufficient time for data preparation.
- The earlier steps indata mining projects consume the most time (oftem more than 80%).
- Looking only at aggregated results and not at individual records.
- Being sloppy about keeping track of the data mining procedure and results.
- Using data from the future to predict the future.
- Ignoring suspecious findings and quickly moving on.
- Ignoring the subject matter experts.
- Believing everything you are told about the data (become a data skeptic).
- Assuming that the keepers of the data will be fully on board with cooperation. one of the biggest obstacles in data mining projects can be the people who own and control the data.
- Assuming that you are done when the model is built, it needs to be deployed to be useful.
Practical Tips:
- The goal of a knowledge discovery / data mining project should be to show incremental and continous value added, as opposed to taking on a large project that will consume resources without producing any valuable outcomes.
- Each algorithm has its own unique way of processing data, and knowing that is necessary to get the most out of each model type.
- Producing the results in a measure and format that appeals to the end user tremendously increases the likelihood of true understanding and propoer use of the data mining outcomes.