Chapter 5
Predictive Analytics 2: text, web, and social media analytics.
- According to a study by Merril Lynch and Gartner, 85% of all corporate data is captured and stored in some sort of unstructured form.
- The same study also stated that this unstructured data is doubling in size every 18 months.
1. What is Text Analytics?
Text Analytics = Information Retreival + Text Mining
The text analytics map:
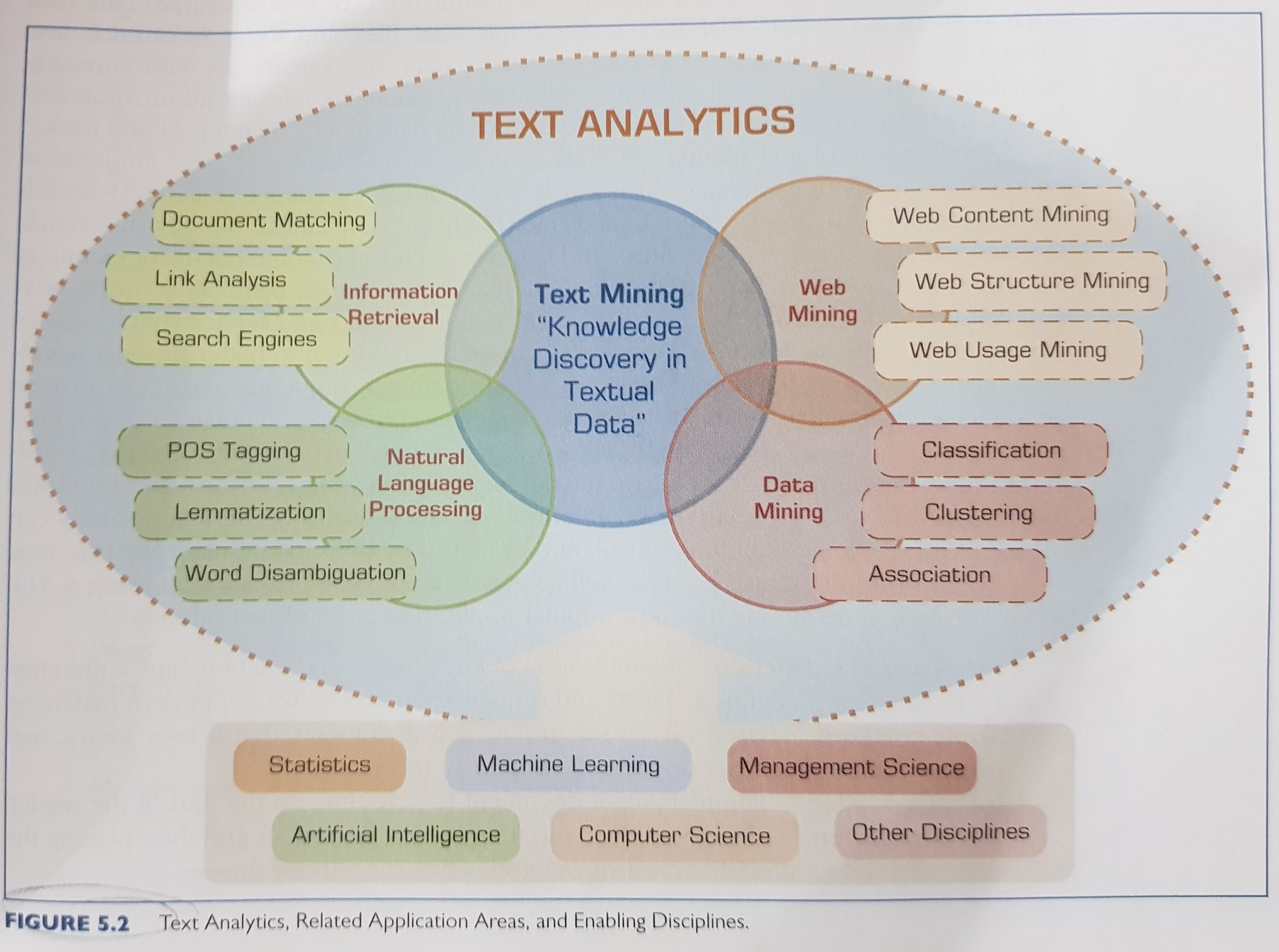
The following list describes some commonly used text mining terms:
- Unstructured data (versus structured data).
Structured data has a predetermined format. It is usually organized into records with simple data values (categorical, ordinal, and continuous variables) and stored in databases. In contrast, unstructured data does not have a predetermined format and is stored in the form of textual documents. In essence, the structured data is for the computers to process while the unstructured data is for humans to process and understand.
- Corpus.
In linguistics, a corpus (plural corpora) is a large and structured set of texts (now usually stored and processed electronically) prepared for the purpose of conducting knowledge discovery.
- Terms.
A term is a single word or multiword phrase extracted directly from the corpus of a specific domain by means of natural language processing (NLP) methods.
- Concepts.
Concepts are features generated from a collection of documents by means of manual, statistical, rule-based, or hybrid categorization methodology. Compared to terms, concepts are the result of higher level abstraction.
- Stemming.
Stemming is the process of reducing inflected words to their stem (or base or root) form. For instance, stemmer, stemming, stemmed are all based on the root stem.
- Stop words.
Stop words (or noise words) are words that are filtered out prior to or after processing of natural language data (i.e., text). Even though there is no universally accepted list of stop words, most natural language processing tools use a list that includes articles (a, am, the, of, etc.), auxiliary verbs (is, are, was, were, etc.), and context-specific words that are deemed not to have differentiating value.
- Synonyms and polysemes.
Synonyms are syntactically different words (i.e., spelled differently) with identical or at least similar meanings (e.g., movie, film, and motion picture). In contrast, polysemes, which are also called homonyms, are syntactically identical words (i.e., spelled exactly the same) with different meanings (e.g., bow can mean “to bend forward,” “the front of the ship,” “the weapon that shoots arrows,” or “a kind of tied ribbon”).
- Tokenizing.
A token is a categorized block of text in a sentence. The block of text corresponding to the token is categorized according to the function it performs. This assignment of meaning to blocks of text is known as tokenizing. A token can look like anything; it just needs to be a useful part of the structured text.
- Term dictionary.
A collection of terms specific to a narrow field that can be used to restrict the extracted terms within a corpus.
- Word frequency.
The number of times a word is found in a specific document.
- Part-of-speech tagging.
The process of marking up the words in a text as corresponding to a particular part of speech (such as nouns, verbs, adjectives, adverbs, etc.) based on a word’s definition and the context in which it is used.
- Morphology.
A branch of the field of linguistics and a part of natural language processing that studies the internal structure of words (patterns of word formation within a language or across languages).
- Term-by-document matrix (occurrence matrix).
A common representation schema of the frequency-based relationship between the terms and documents in tabular format where terms are listed in rows, documents are listed in columns, and the frequency between the terms and documents is listed in cells as integer values.
- Singular-value decomposition (latent semantic indexing).
A dimensionality reduction method used to transform the term-by-document matrix to a manageable size by generating an intermediate representation of the frequencies using a matrix manipulation method similar to principal component analysis.
A popular example of a recent breakthrough in text analytics, IBM Watson (DeepQA) architecture:
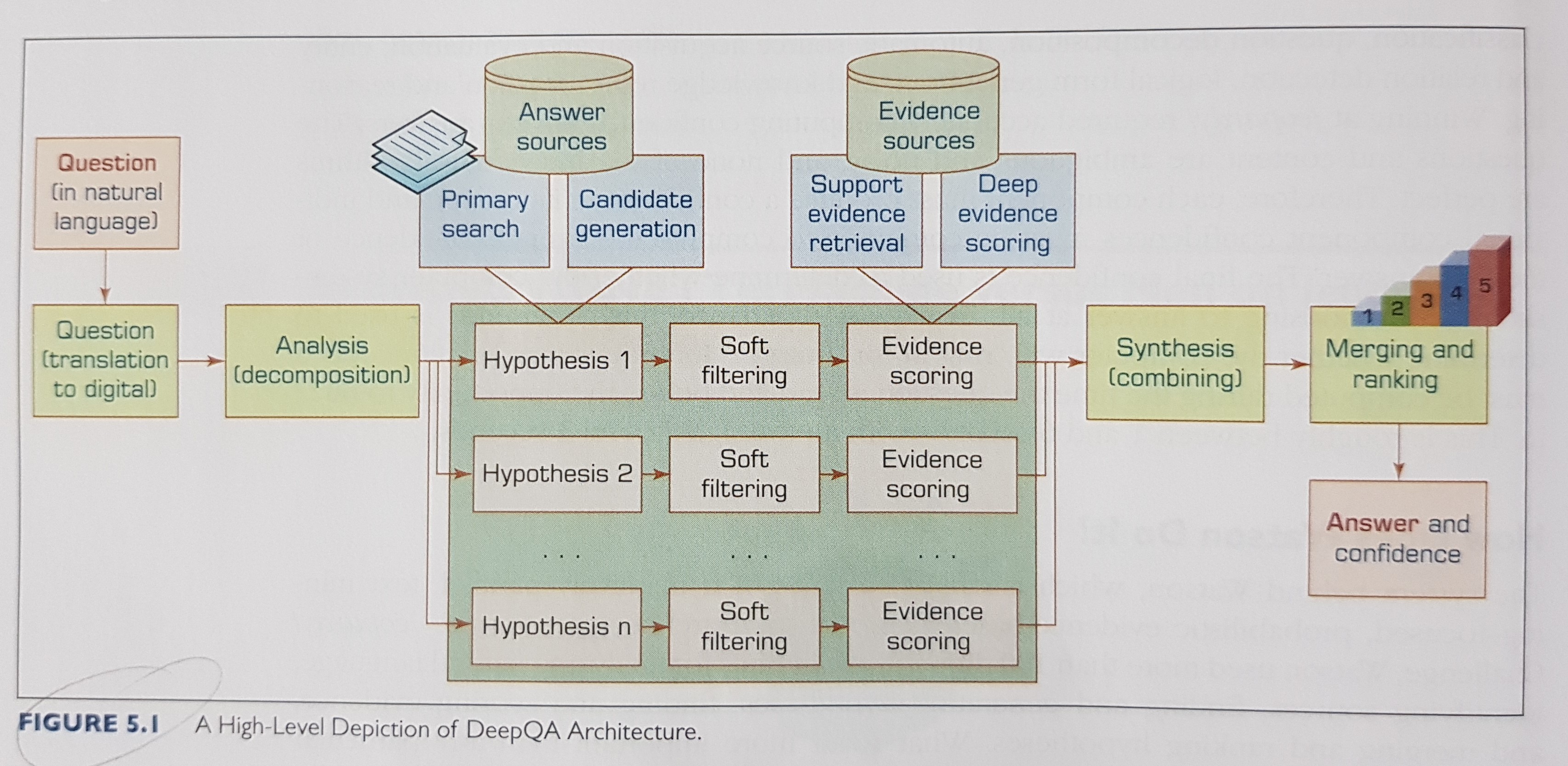
2. Natural Language Processing (NLP)
The goal of NLP is to move beyond synatx driven text manipulation (which is often calld “word counting”) to a true understanding and processing of natural language that considers grammatical and semantic constraints as well as the context.
NLP tasks:
- question answering
- automatic summarization
- natural language generation
- natural language understanding
- machine translation
- foreign language reading
- foreign language writing
- speech recognition
- text-to-speech
- text proofing
- optical character recognition
Should be useful: WordNet is a lexical database of semantic relations between words (available in many languages).
3. Text Mining
The text mining process:
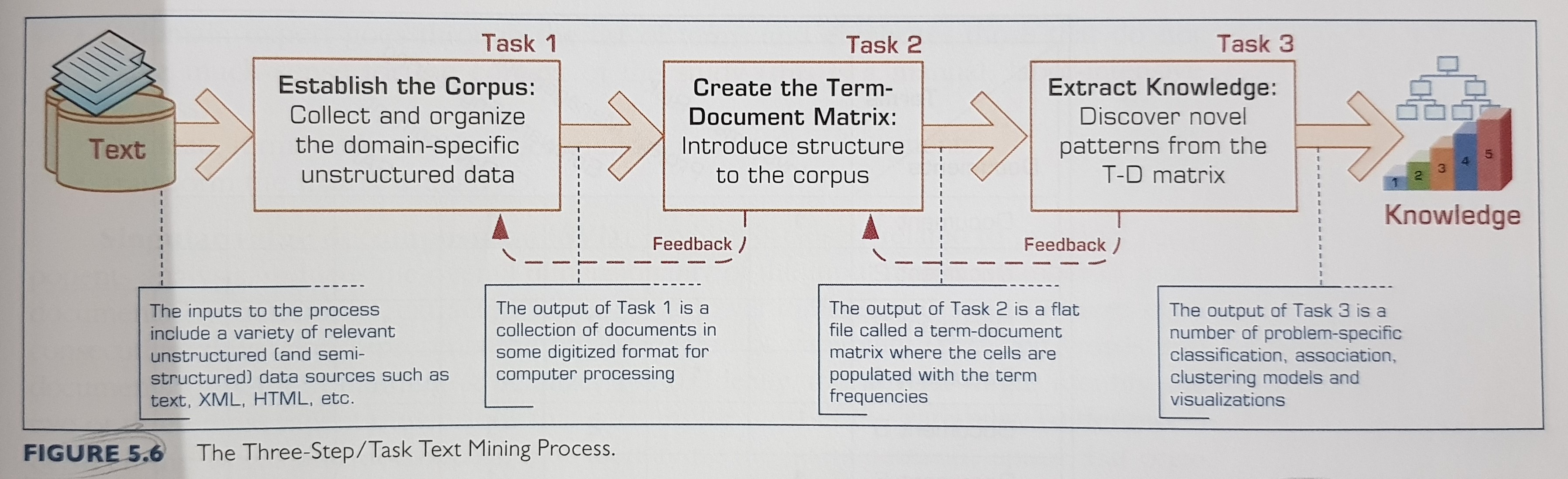
Building a term-document matrix:
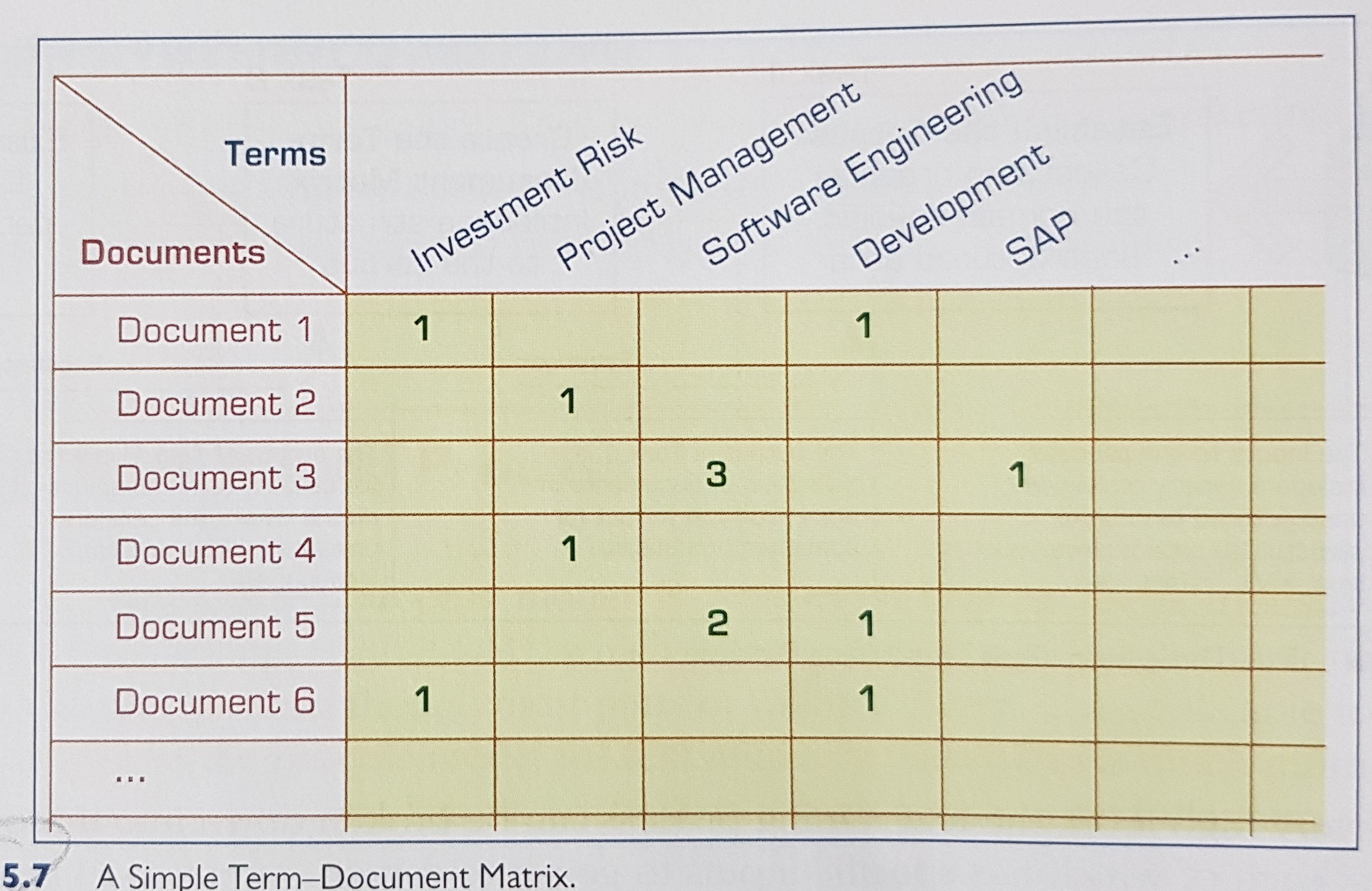
Note: This term count per docuemnt needs to be normalized (per document) to make a fair assessment of the importance of the terms in a document.
Once a certain level of structure is achieved, then we can use:
- classification, for text categorization.
- clustering, for similarity and search.
- trend analysis.
4. Sentiment Analysis
Sentiment can be defined as a settled opinion reflective of one’s feelings.
Sentiment analysis deals with:
- two classes…
- a range of polarity…
- or even a range in strength of opinion.
Sentiment analysis applications:
- voice of the customer
- voice of the market
- voice of the employee
- brand management
- financial markets
- politics
- government intelligence
Sentiment analysis process:
- sentiment detection (with differentiation between objectve and subjective).
- n-p polarity classification.
- target identification.
- collection and aggregation.
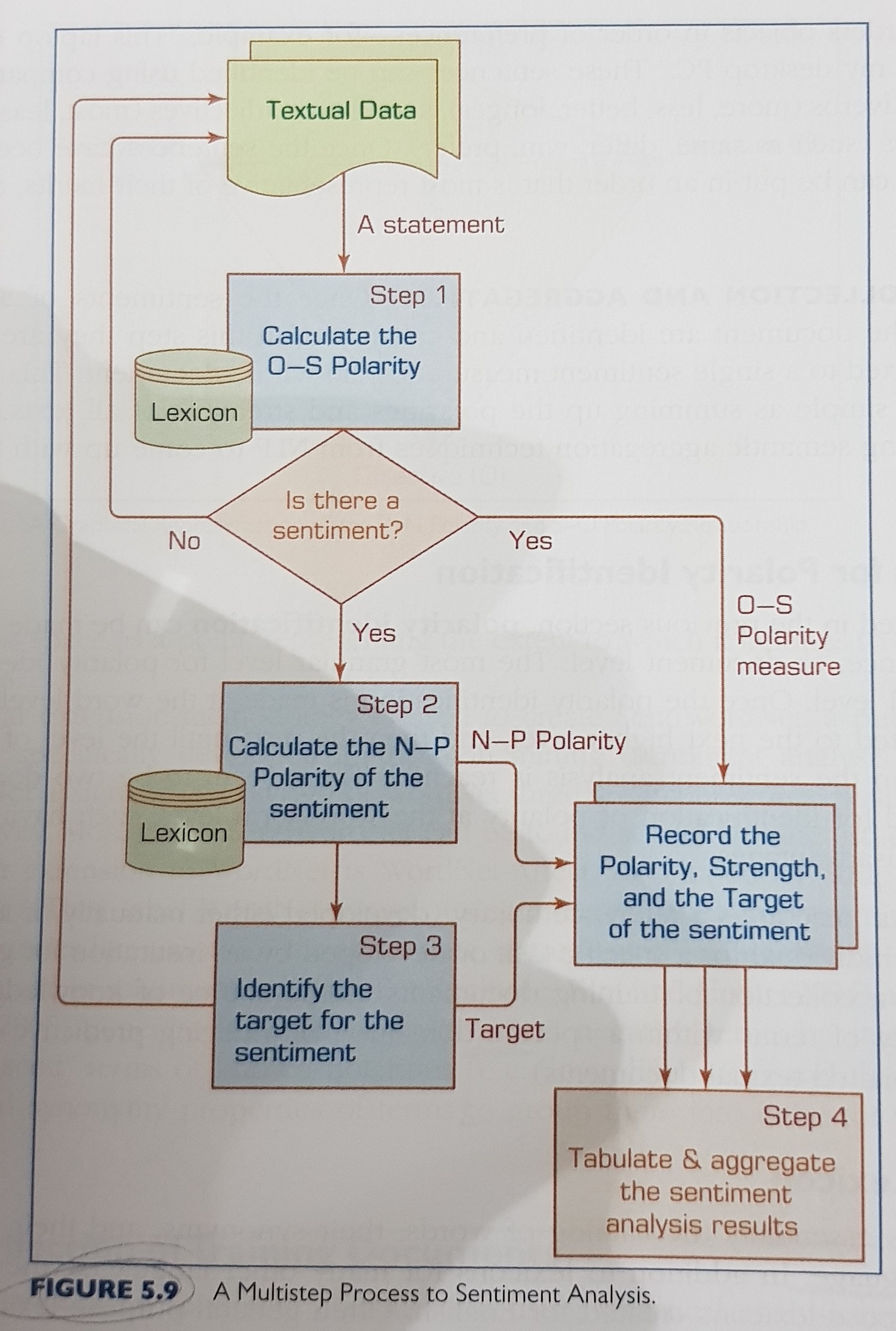
Methods for polarity identification
- using a lexicon
- using a collection of training documents
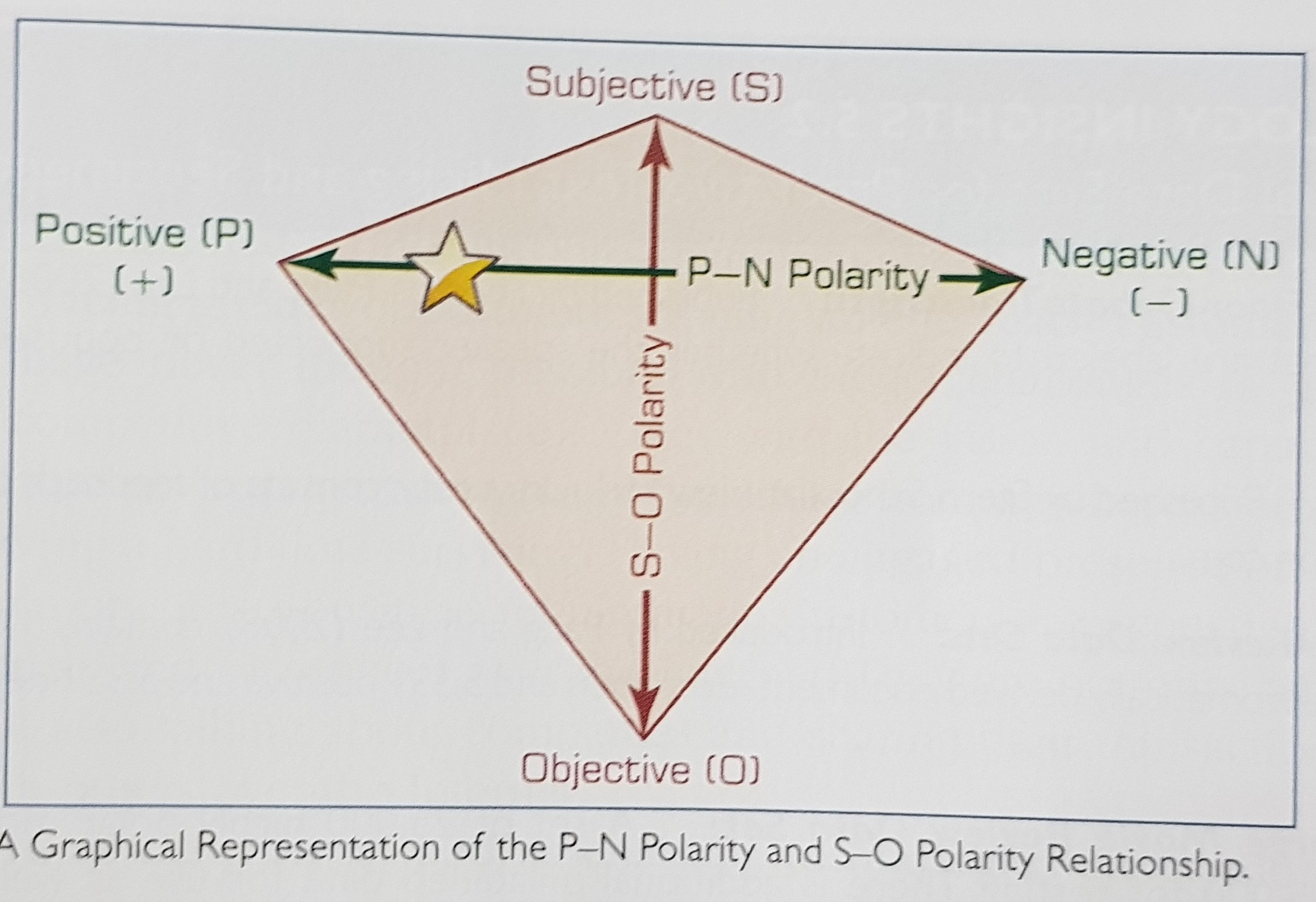
Remark: Sentiment orientation of the document may not make sense for very large docuemnts. Therefore, it is often used on a small to medium sized documents.
5. Web Mining
A simple taxonomy of web mining:
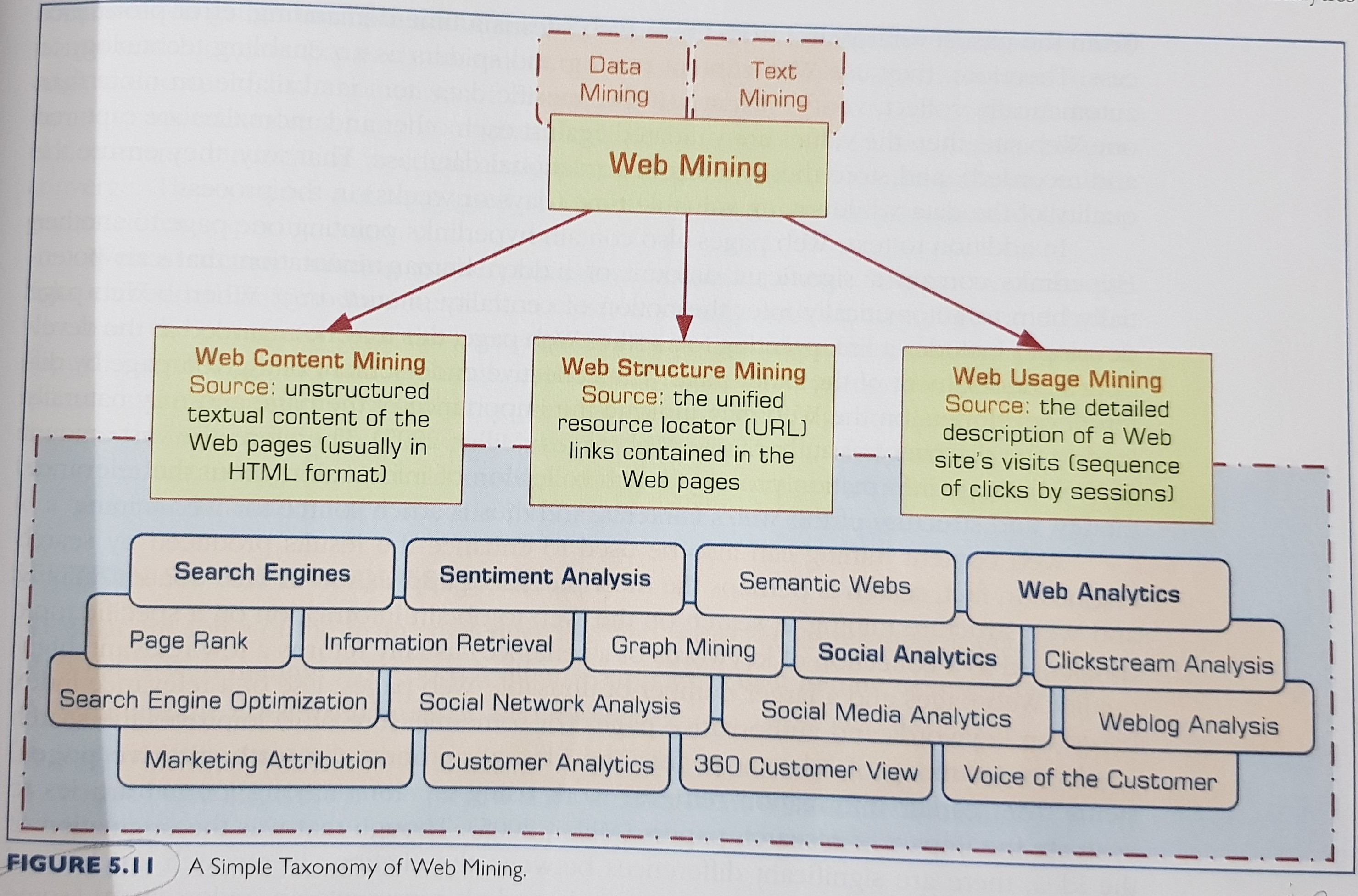
Tip: do not post links of your competitor on your website, this might be regarded as endorsement
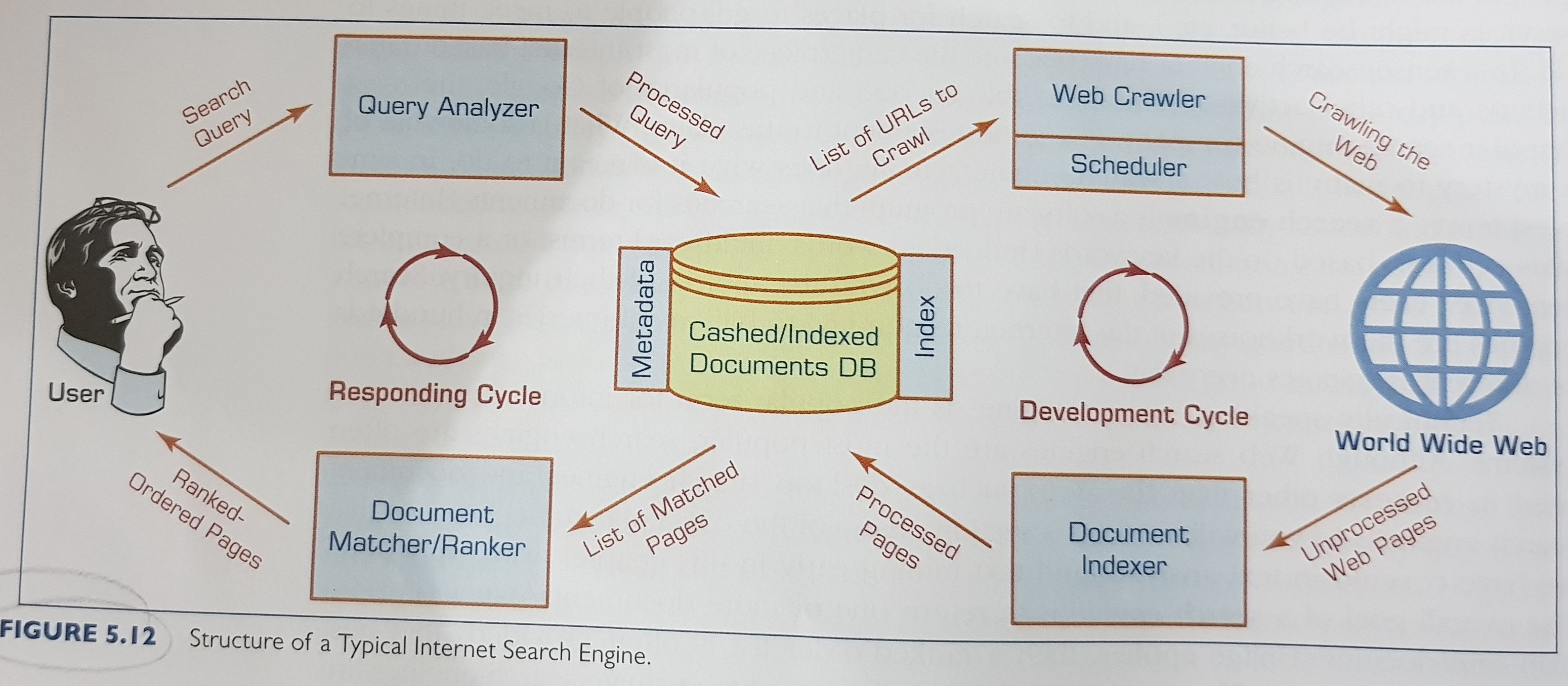
Search engine structure:
Important / actionable web analytics metrics:
- website usability
- page views
- time on site
- downloads
- click map
- click path
- traffic soures
- referral web sites
- search engines
- direct
- offline campaigns
- online campaigns
- visitor profiles
- keywords
- content groupings
- geography
- time of day
- landing page profiles
- conversion statistics
- new visitors
- returning visitors
- leads
- sales/conversions
- abandonment/exit rates
6. Social Networks
Social networks are self-organizing, emergent, and complex, such athat a globally coherent pattern appears from the local interaction of the elements that make up the system.
Types of social networks:
- communication networks
- community networks
- criminal networks
- innovation networks
Metrics for understanding social networks:
- conections
- homophily
- multiplexity
- mutuality/reciprocity
- network closure
- propinquity
- distributions
- bridge
- centrality
- density
- distance
- structural holes
- tie strength
- segmentation
- cliques and social circles
- clustering coefficient
- cohesion
Prevailing characteristics that help differentiate between social and industrial media:
- quality
- reach
- frequency
- accessibility
- usability
- immediacy
- updatabiliy
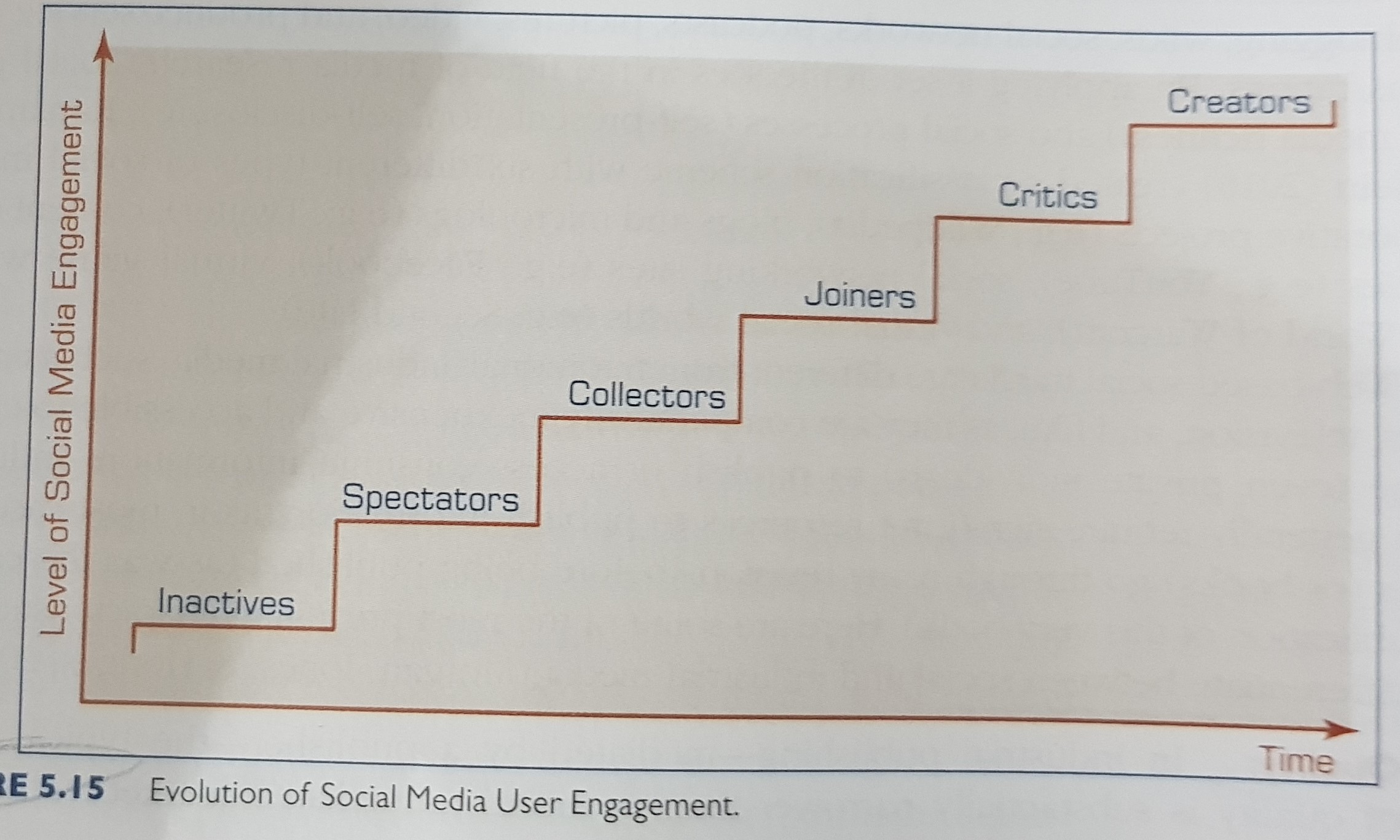
Evolution of social media user engagement:
Best practices in social media analytics:
- think of measurement as a guidance system, not a rating system
- track the elusive sentiment
- continuously improve the accuracy of text analysis
- look at the ripple effect
- look beyond the brand
- identify your most powerful influencers
- look closely at the accuracy of your analytic tool
- incorporate social media intelligence into planning