Chapter 7
Big Data Concepts and Tools.
1. Introduction
Big Data is data that gives you trouble in:
- capture
- processing
- storage
- management
The “V”s that define big data:
- volume
- variety
- velocity – at rest analytics vs. stream analytics
- veracity – conformity to facts
- variability – highly inconsistent and with periodic peaks
- value proposition
Big data by itself is useless unless someone does something with it that delivers value.
The critical success factors for big data analytics are:
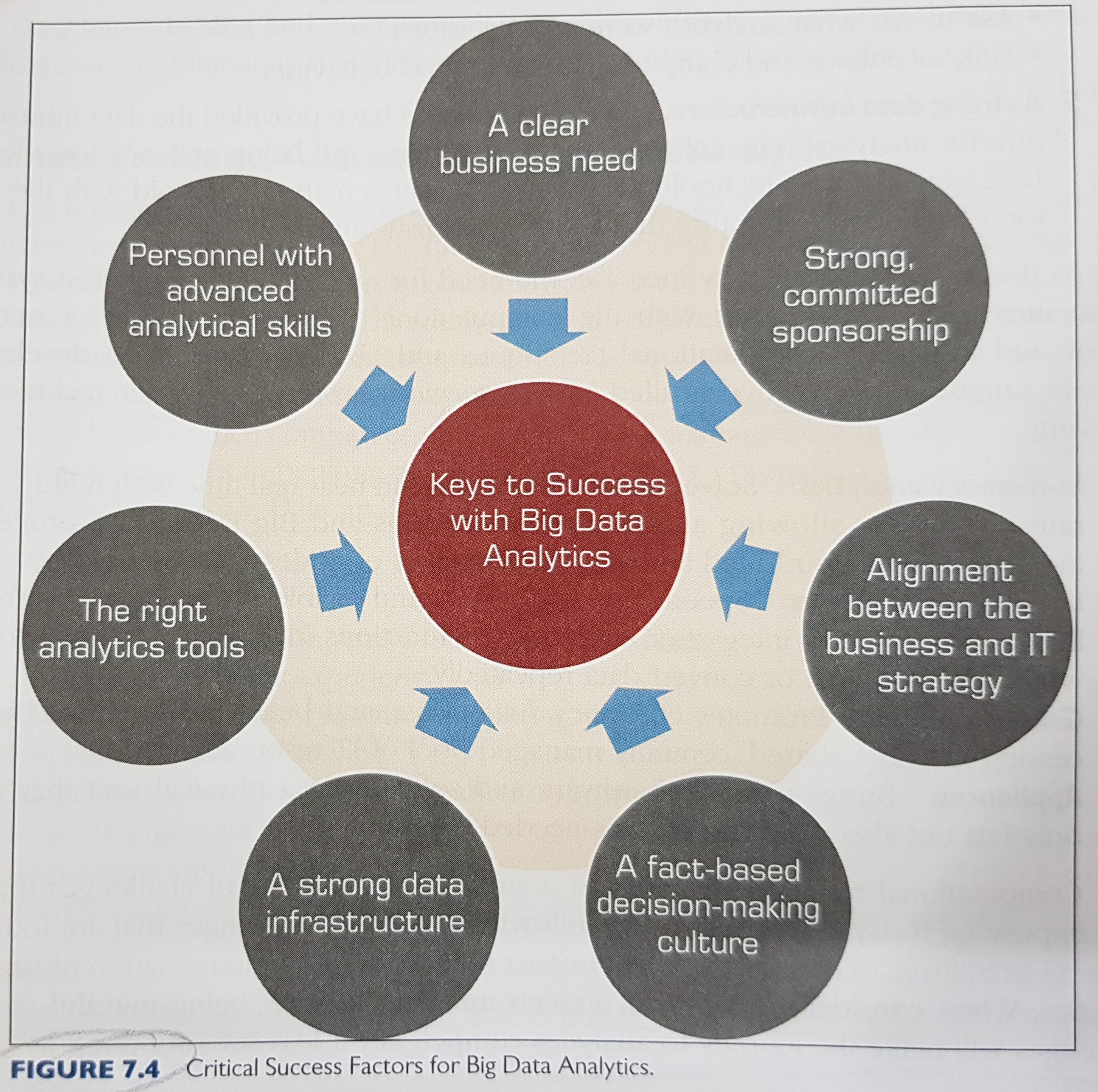
High performance computing techniques:
- in-memory analytics
- in-database analytics
- grid computing
- appliances
Things to be aware of when considering big data projects:
- data volume
- data integration
- processing capabilities
- data governance
- skills availability
- solution cost
2. Big Data Technologies
- they take advantage of comodity hardware to enable scale and parallel processing techniques.
- they employ non relational data storage capabilities to process unstructured and semistructured data.
- they apply advanced analytics and data visualization technology to big data to convey insights to end users.
The three big data technologies:
- MapReduce
- Hadoop
- NoSQL
Note: it is best to think of them as an ecosystem (mostly of open source software), not a single product.
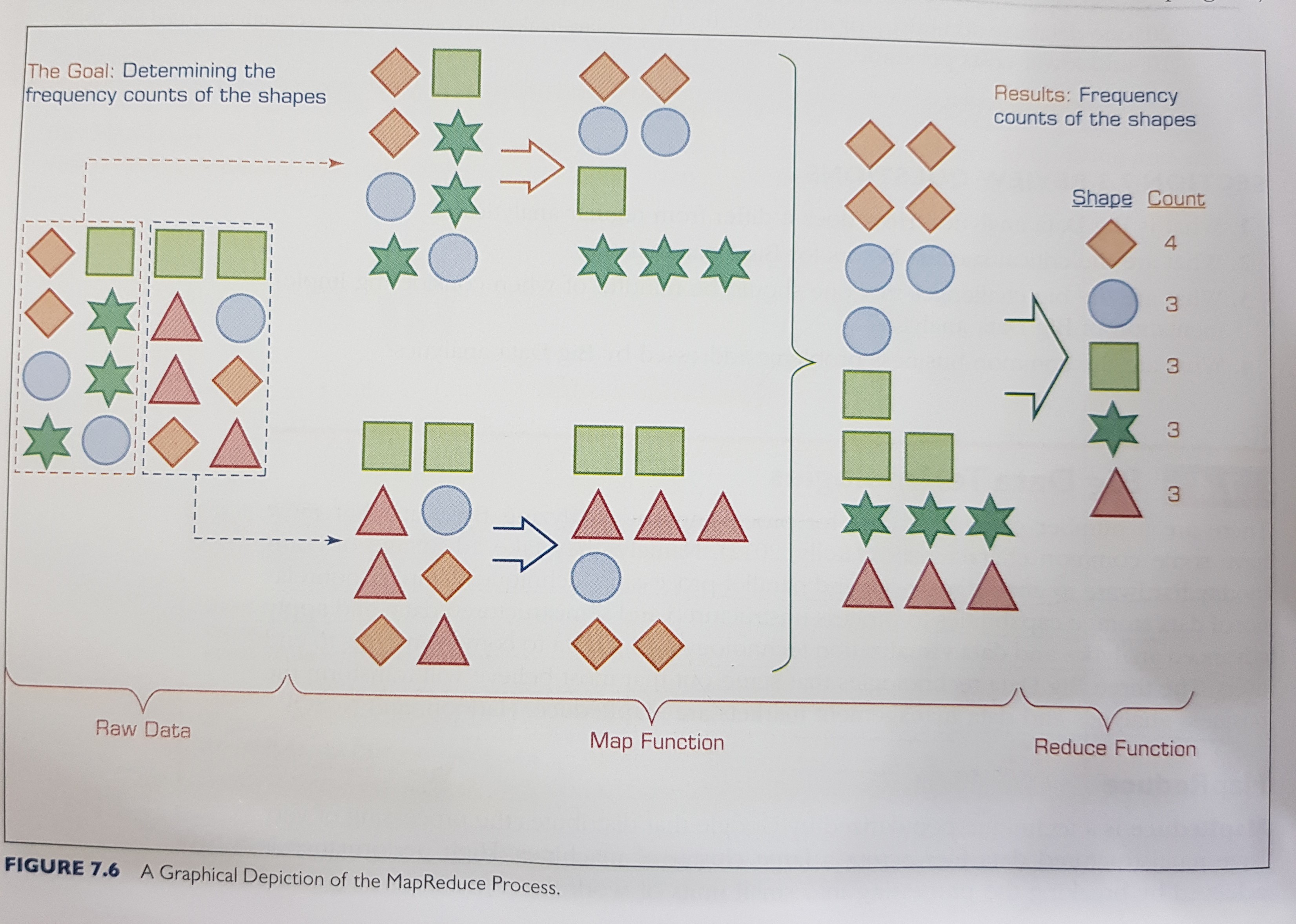
MapReduce
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Programs written in this functional style are automatically parallelized and executed on a large cluster of commodity machines. This allows programmers without any experience with parallel and distributed systems to easily utilize the resources of a large distributed system.
Hadoop
Its fundamental concept is that rather than banging away at one huge block of data with a single machine, hadoop breaks up big data into multiple parts so each part can be processed and analyzed at the same time.
- Hadoop sits at both ends of the large-scale data life cycle:
- First when raw data is born…
- and finally when data is retiring, but is still occasionally needed.
- Therefore, Hadoop can be used as an active / always on archive.
Hadoop techincal components:
- HDFS – a file system, not a DBMS
- name node
- secondary node
- job tracker
- slave nodes
Hadoop ecosystem / complementary subprojects:
- Hive, an open source data warehouse – resembles SQL, but it is not standard SQL.
- Mahout, for data science.
- Hcatalog, for meta data management.
Important remarks:
- Hadoop is about data diversity, not just data volume.
- Hadoop compliments a DW; it is rarely a replacement.
Hadoop vs. a DW
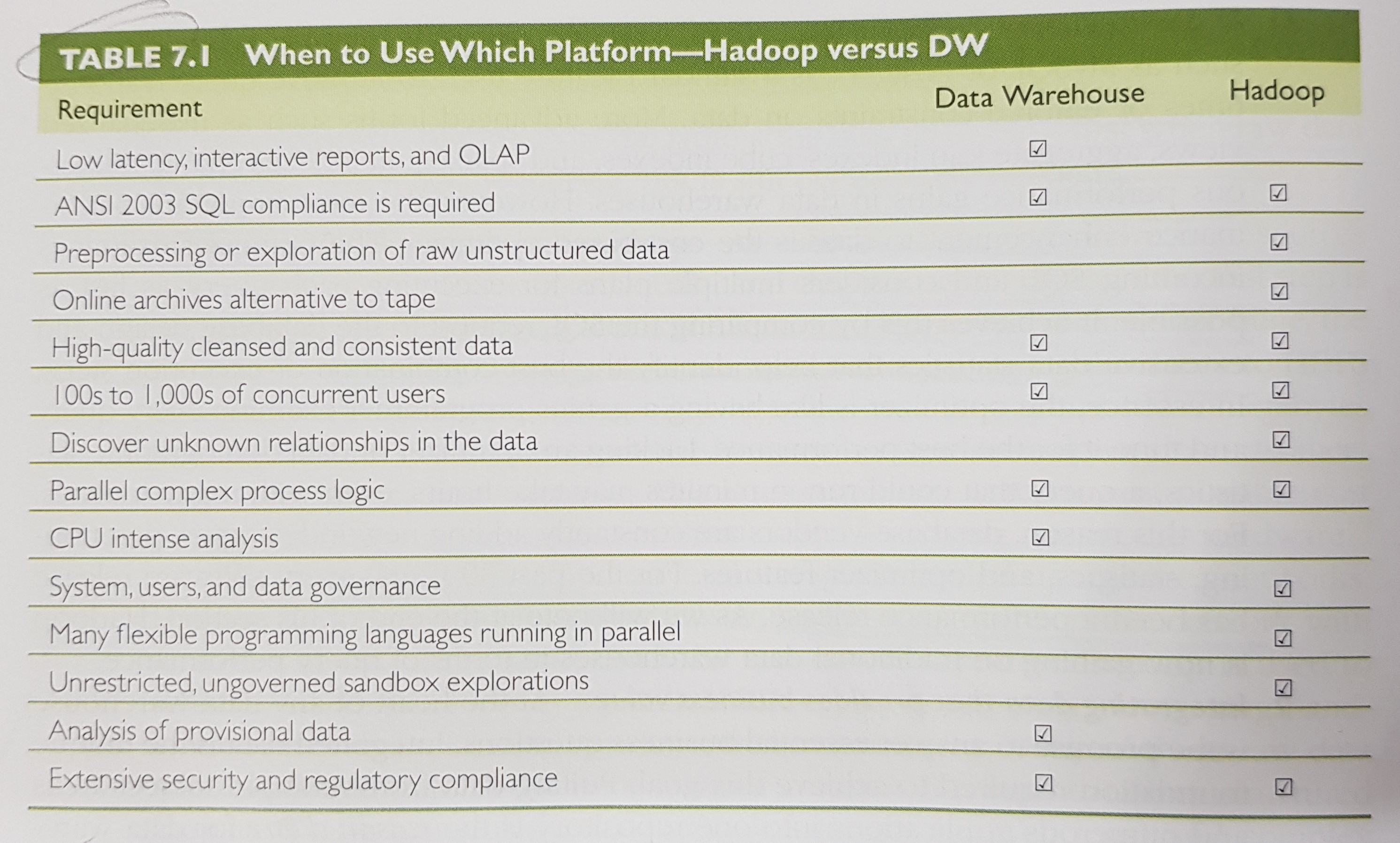
Hadoop coexistence with a DW
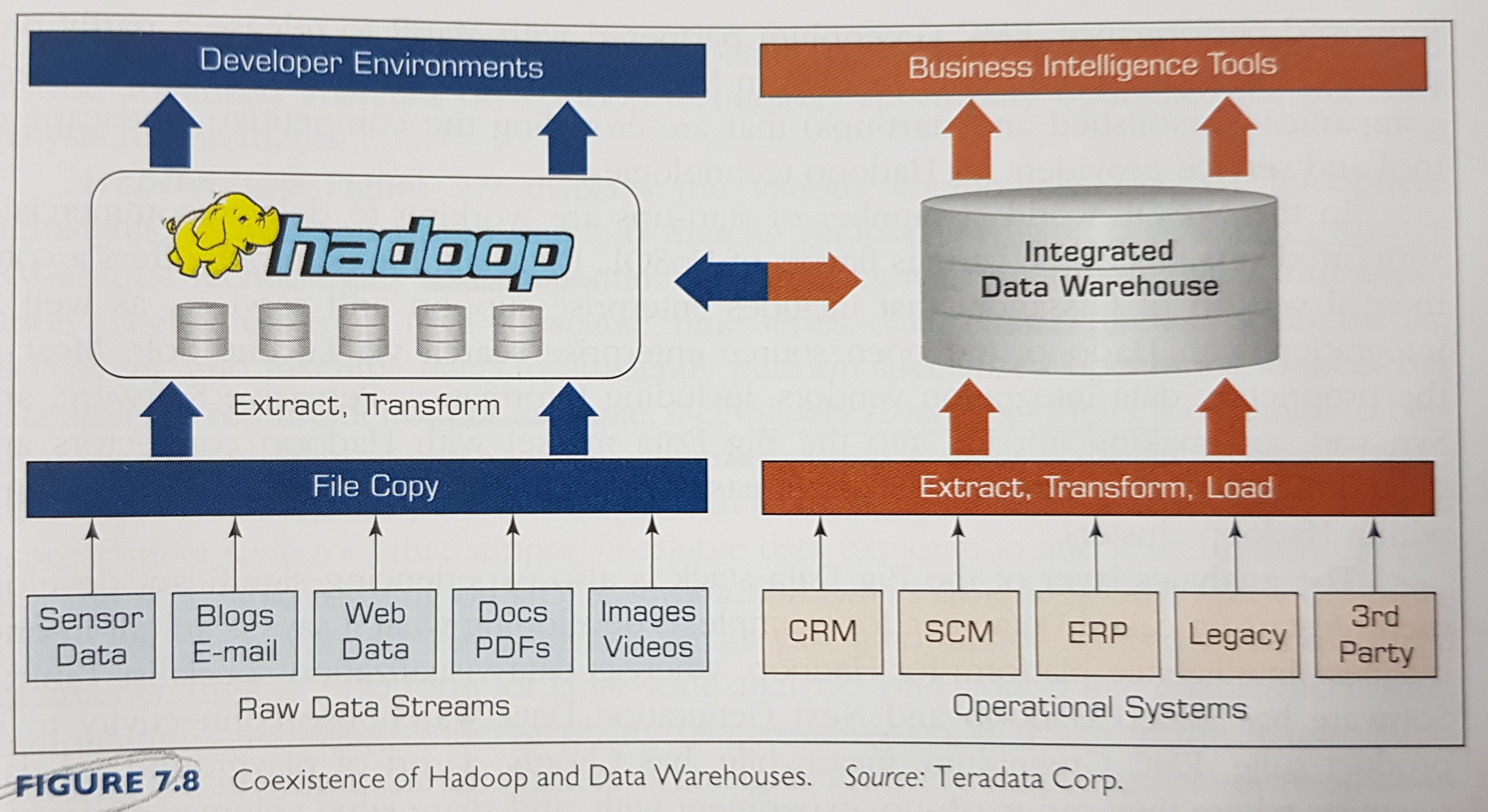
The coexistence of Hadoop and DW:
- use hadoop for storing and archiving multistructured data.
- use hadoop for filtering, transforming, and/or consolidating multistructured data.
- use hadoop to analyze large volumes of multistructured data and publish the analytics results.
- use a relational DBMS that provides mapreduce capabilities as an investigative computing platform.
- use a front-end query tool to access and anlyze data.
NoSQL (Not only SQL)
- Offers schema on read (not like the traditional of schema on write).
- The downside of most NoSQL databases today is that they trade ACID (atomicity, consistency, isolation, durability) compliance for performance and scalability.
- Many also lack mature management and monitoring tools.
New / Emerging
Stream analytics == data in motion analytics == real time data analytics.